
es.wedoany.com Noticia: Un equipo de nueve investigadores de Sina Weibo ha lanzado VibeThinker-3B, un modelo de lenguaje compacto con 3 mil millones de parámetros, que en múltiples pruebas de referencia de razonamiento iguala o supera los resultados de sistemas más grandes de instituciones como Google DeepMind, OpenAI, la empresa de seguridad en inteligencia artificial Anthropic y DeepSeek.
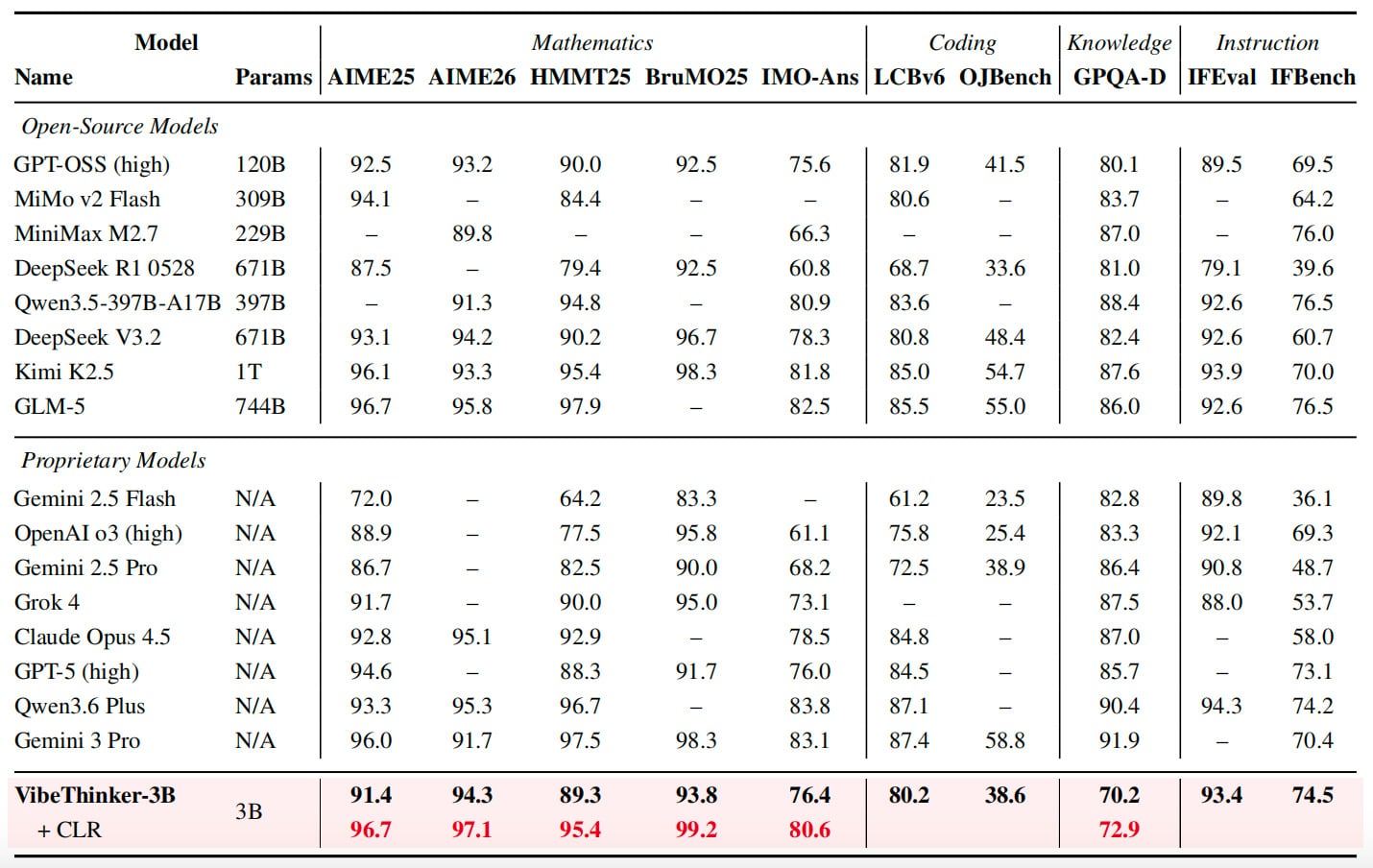
El modelo obtuvo 94,3 puntos en AIME 2026, comparable al rendimiento de DeepSeek V3.2, que tiene 671 mil millones de parámetros, y superó los 91,7 puntos de Gemini 3 Pro. Mediante un método de escalado en tiempo de prueba denominado "Evaluación de Fiabilidad a Nivel de Afirmación" (Claim-Level Reliability Assessment), la puntuación de VibeThinker-3B en AIME 2026 mejoró aún más hasta 97,1.
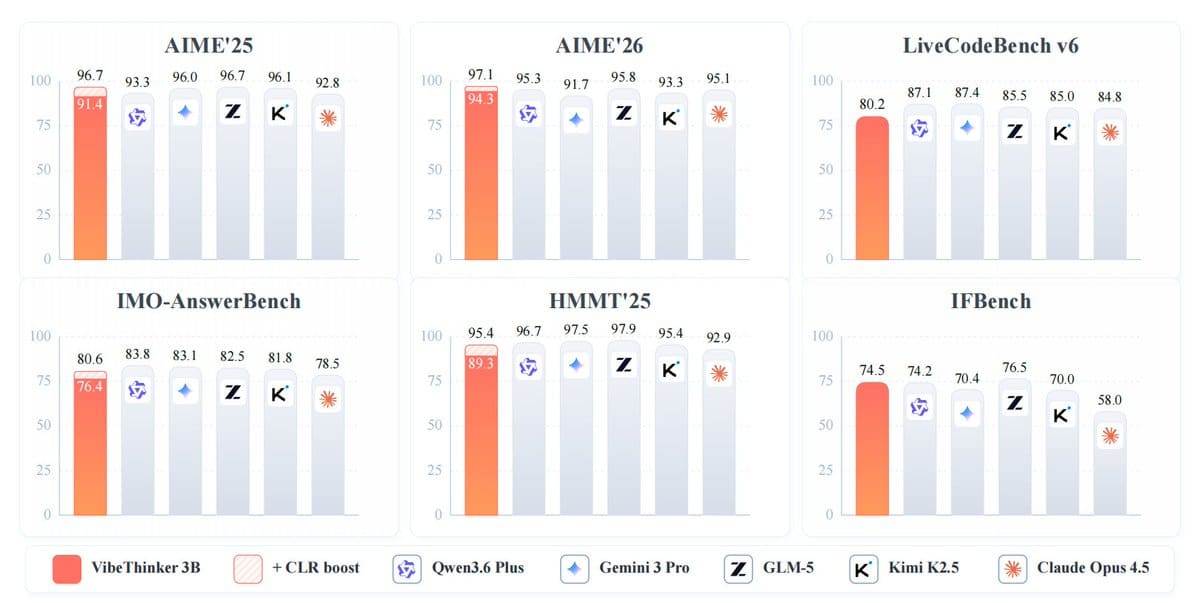
En otras pruebas de referencia, VibeThinker-3B obtuvo 91,4 en AIME 2025, 89,3 en HMMT 2025, 93,8 en BruMO 2025 y 76,4 en IMO-AnswerBench. En cuanto a capacidad de codificación, el modelo logró una puntuación Pass@1 de 80,2 en LiveCodeBench v6 y una tasa de aceptación de envíos del 96,1% en concursos semanales y quincenales de LeetCode no vistos, realizados entre finales de abril y finales de mayo de 2026. En la prueba de seguimiento de instrucciones IFEval, obtuvo 93,4.
El modelo superó 123 de 128 problemas de LeetCode en su primer envío, superando a GPT-5.2, Doubao Seed 2.0 Pro, Kimi K2.5 y Claude Opus 4.6 en las mismas condiciones de evaluación.
VibeThinker-3B tiene aproximadamente 224 veces menos parámetros que DeepSeek V3.2. En comparación, GLM-5 tiene 744 mil millones de parámetros, mientras que Kimi K2.5 supera el billón. El modelo es lo suficientemente pequeño como para ejecutarse en ordenadores portátiles de consumo. El equipo de investigación cree que las tareas de razonamiento verificables, como matemáticas y codificación, pueden comprimirse de manera más eficiente en modelos pequeños que el conocimiento fáctico amplio, denominando a esto la "hipótesis de cobertura de compresión de parámetros".
El modelo no destaca en todos los ámbitos. En la prueba GPQA-Diamond, obtuvo 70,2 puntos, frente a los 91,9 de Gemini 3 Pro y los 87,0 de Claude Opus 4.5. El equipo de investigación afirma que esto respalda su argumento de que los modelos compactos pueden rendir bien en tareas de razonamiento verificables, pero no pueden reemplazar a los modelos grandes que ofrecen una cobertura de conocimiento más amplia.
VibeThinker-3B se basa en Qwen2.5-Coder-3B de Alibaba y se mejora mediante un proceso de post-entrenamiento de cuatro etapas. La primera etapa utiliza aprendizaje supervisado con datos de matemáticas, codificación, razonamiento STEM, diálogo y seguimiento de instrucciones, para luego pasar a problemas de razonamiento más difíciles y largos. En las muestras de entrenamiento, se eliminaron aquellas con trazas de razonamiento de menos de 5000 tokens, así como las que la versión anterior VibeThinker-1.5B podía resolver más del 75% de las veces. La segunda etapa emplea optimización de políticas guiada por entropía máxima (MaxEnt-Guided Policy Optimization) con aprendizaje por refuerzo en tareas de matemáticas, codificación y STEM. Los investigadores utilizaron una única ventana de 64 000 tokens en lugar de expandir gradualmente la ventana de contexto, ya que la expansión progresiva reducía el rendimiento en la escala de 3B. Una etapa independiente de "aprendizaje por refuerzo de matemáticas de largo a corto" (Long2Short Math RL) recompensa las respuestas correctas más cortas para reducir la verbosidad innecesaria. La tercera etapa destila las trazas de razonamiento exitosas de los puntos de control de aprendizaje por refuerzo de vuelta al modelo unificado. La etapa final aplica aprendizaje por refuerzo a tareas de seguimiento de instrucciones utilizando comprobaciones basadas en reglas y un modelo de recompensa.
Los resultados de las pruebas han generado atención, pero también preocupaciones sobre un posible sobreajuste del modelo a las pruebas de referencia. Algunos usuarios informan que el modelo tiene un rendimiento más débil en problemas de codificación reales, incluyendo dificultades con herramientas de desarrollo comunes. También se cuestiona por qué no se probó el modelo en pruebas de referencia de ingeniería de software más amplias. Los investigadores afirman que los datos de entrenamiento se sometieron a un riguroso proceso de descontaminación de pruebas de referencia, incluyendo el filtrado de texto superpuesto. Los concursos recientes de LeetCode ofrecen una mayor protección contra la fuga de datos, ya que estos concursos ocurren después de cualquier posible fecha de corte de entrenamiento. Sin embargo, los informes de usuarios aún indican una brecha entre las puntuaciones de las pruebas de referencia y el rendimiento real.
El modelo se publica bajo la licencia MIT y sus pesos están disponibles a través de Hugging Face y ModelScope. En el primer día de su lanzamiento, los desarrolladores ya habían generado versiones cuantizadas GGUF y modelos derivados.
Sina Weibo es más conocido por su plataforma de redes sociales que por su investigación de vanguardia en IA. VibeThinker-3B es la segunda publicación importante de código abierto de IA de la empresa en siete meses. VibeThinker-1.5B, lanzado en noviembre de 2025, supuestamente superó al DeepSeek R1 original en múltiples pruebas de referencia de matemáticas. El equipo afirma que su costo de post-entrenamiento fue de 7800 dólares, mientras que el costo estimado de DeepSeek R1 fue de 294 000 dólares.
Los investigadores no afirman que VibeThinker-3B pueda reemplazar a los modelos grandes de propósito general. Creen que, en sistemas de IA híbridos, los modelos pequeños pueden manejar tareas de razonamiento, mientras que los sistemas grandes proporcionan conocimiento fáctico. Este enfoque podría reducir el costo de implementar razonamiento avanzado y ofrecer potentes capacidades matemáticas y de codificación en dispositivos con hardware limitado. La cuestión clave es si el rendimiento del modelo en las pruebas de referencia se traduce en aplicaciones fiables en el mundo real.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com










