
es.wedoany.com Noticia: Se ha lanzado el modelo de audio de alta velocidad AudioX-Turbo, que genera 10 segundos de audio en 0.24 segundos con solo 4 pasos de inferencia. Desarrollado por Noiz AI en colaboración con la Universidad de Ciencia y Tecnología de Hong Kong y la Universidad de Tsinghua, este modelo admite entradas multimodales como texto, video e imagen. Mediante técnicas de destilación por emparejamiento de distribuciones y destilación adversarial, comprime el proceso de generación de los modelos de difusión tradicionales, que requieren de 50 a 200 pasos, a solo 4 pasos, reduciendo el número de evaluaciones del modelo en aproximadamente 25 veces. En una sola tarjeta gráfica RTX 4090, genera 10 segundos de audio en solo 0.24 segundos, con un factor en tiempo real de solo 0.02, abriendo nuevas posibilidades para la interacción de audio en tiempo real.
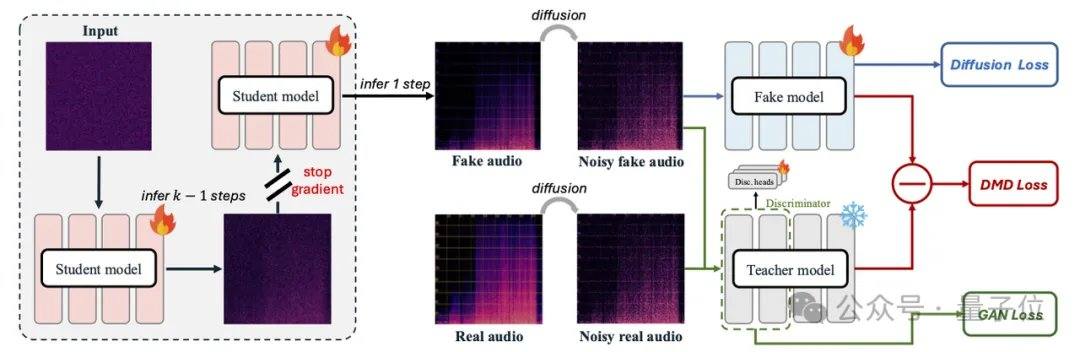
Los modelos de audio actuales más populares, como MMAudio y Stable Audio Open, dependen de técnicas de difusión o flujo matching, que generalmente requieren decenas o cientos de iteraciones. AudioX-Turbo utiliza como base el Transformer de Difusión Multimodal (MMDiT) de fusión multimodal nativa, y junto con el módulo MAF, entrena desde cero 2.7 mil millones de parámetros. En el marco de flujo matching, el equipo de investigación introduce la destilación por emparejamiento de distribuciones (DMD) y la destilación adversarial, comprimiendo el modelo a 4 pasos, mientras que mediante la destilación CFG elimina el costo adicional de NFE. Gracias al discriminador de difusión, el modelo estudiante supera al modelo profesor de 100 pasos en algunos indicadores de rendimiento.
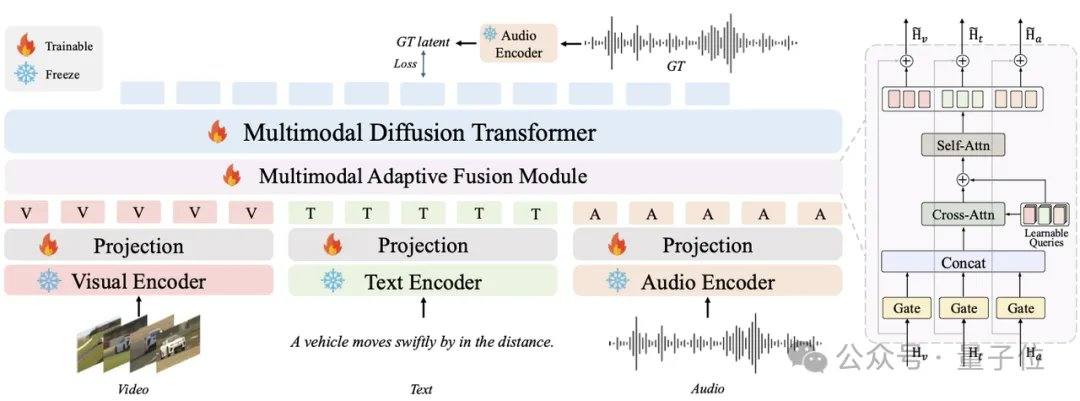
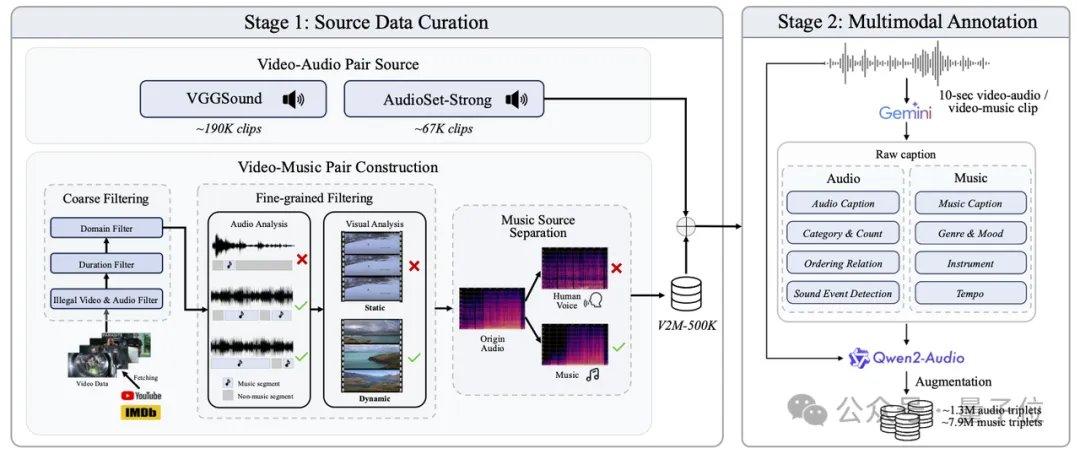
AudioX-Turbo también resuelve el problema del control preciso en los modelos de audio. El equipo de investigación señala que muchos modelos anteriores no podían controlar con precisión las marcas de tiempo, debido a que las etiquetas de texto de los datos de entrenamiento eran demasiado vagas. Para ello, Noiz AI y el equipo de la Universidad de Ciencia y Tecnología de Hong Kong crearon específicamente un conjunto de datos de audio multimodal a gran escala, IF-caps-Pro, con un total de aproximadamente 9.2 millones de muestras. El equipo adoptó un esquema de "anotación en cascada con modelos grandes": primero construyeron una gran cantidad de pares de video-audio de alta calidad, utilizaron el modelo Gemini 2.5 Pro para generar plantillas estructuradas con marcas de tiempo, instrumentos y número de eventos, y luego emplearon Qwen2-Audio para una expansión a gran escala, transformando los datos de "resúmenes vagos" a "guiones con líneas de tiempo precisas".
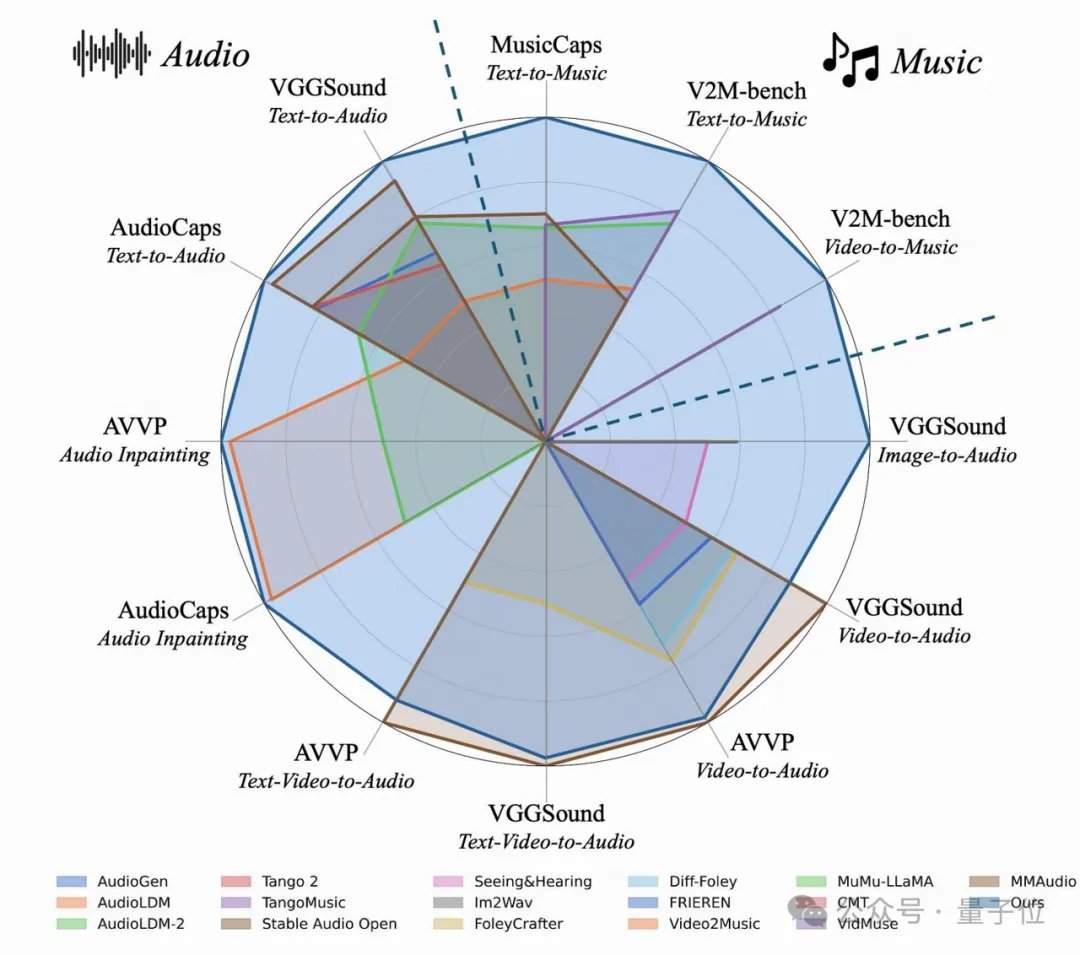
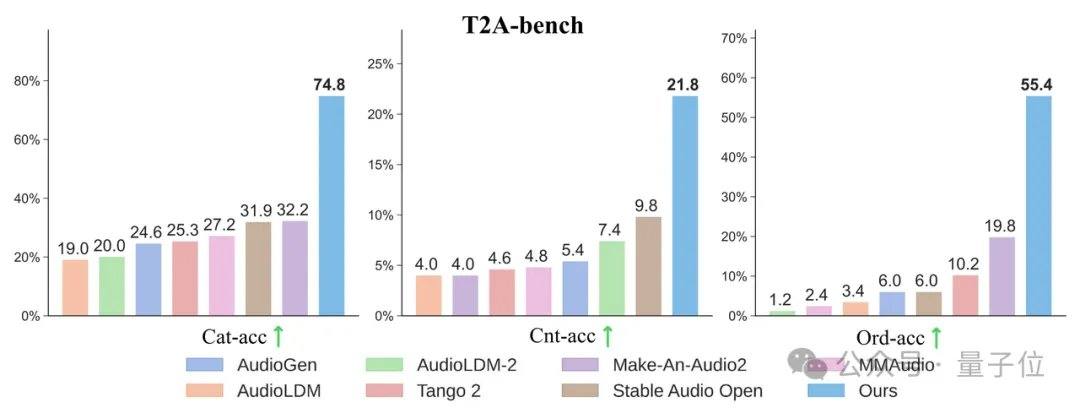
El equipo de investigación descubrió inesperadamente que cuanto más detalladas son las etiquetas de texto, no solo mejora el efecto de generación de audio a partir de texto, sino que también aumenta significativamente la alineación al "doblar videos mudos". En conjuntos de prueba clásicos como AudioCaps y MusicCaps, el modelo AudioX-Turbo de 4 pasos superó o igualó a numerosos modelos de referencia que requieren de 50 a 200 pasos en indicadores clave de calidad de audio. Para evaluar la capacidad de seguir instrucciones, el equipo construyó un benchmark específico, T2A-bench. En las evaluaciones de categoría de sonido, cantidad, marca de tiempo y orden secuencial, AudioX-Turbo mostró un rendimiento abrumador en comparación con otros métodos de referencia, duplicando o más algunos indicadores.
Los tres puntos destacados de AudioX-Turbo incluyen: inferencia en 4 pasos, con una reducción de 25 veces en el costo computacional en comparación con el modelo profesor, mejor rendimiento y un RTF de solo 0.02; un conjunto de datos de 9.2 millones de instrucciones fuertes, logrando por primera vez un control preciso de marcas de tiempo; y soporte para entradas multimodales como texto, video e imagen, permitiendo la generación de Anything-to-Audio. Todo el código de entrenamiento y los pesos del modelo de este proyecto se han publicado como código abierto. El artículo se titula "AudioX-Turbo: A Unified Framework for Efficient Anything-to-Audio Generation", realizado por los equipos de Noiz AI, la Universidad de Ciencia y Tecnología de Hong Kong y la Universidad de Tsinghua. La página del proyecto es https://zeyuet.github.io/AudioX-Turbo/.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com









