
es.wedoany.com Noticia: El equipo emergente chino Catnip ha lanzado recientemente el modelo de audio y video en streaming MaineCoon, capaz de generar contenido audiovisual sincronizado en tiempo real durante más de 30 minutos, alcanzando una velocidad de inferencia de 47.5 FPS en una sola GPU H100, con un costo por segundo inferior a 0.001 dólares.
MaineCoon ha sido desarrollado por un equipo emergente de solo 10 personas, Catnip, con sede en China. El proyecto se inició oficialmente en marzo de este año, y tres investigadores principales completaron en dos meses la entrega integral del entrenamiento del modelo, diseño de arquitectura, infraestructura de datos y sistema de inferencia.
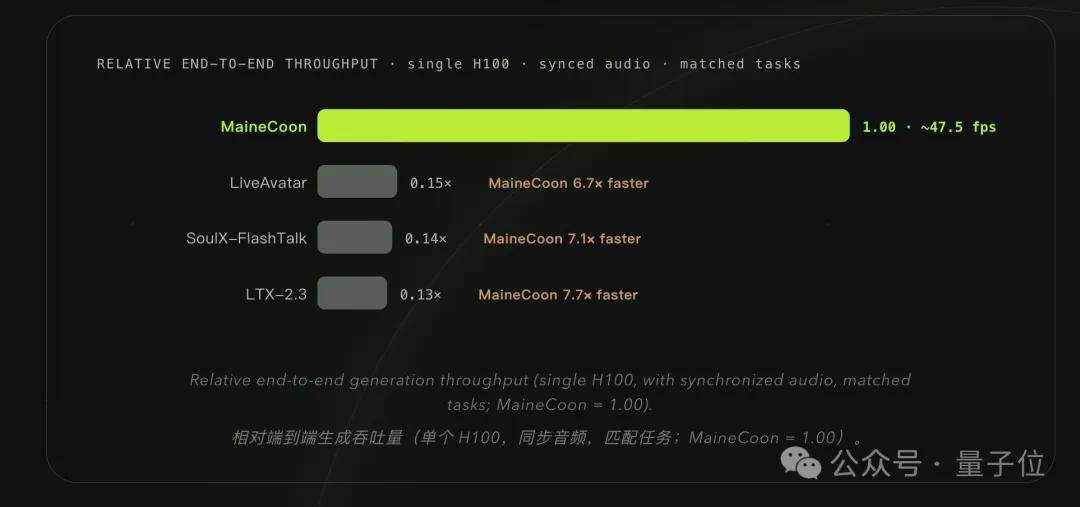
A diferencia de los modelos tradicionales de generación de audio y video, MaineCoon enfoca por primera vez su aplicación en la interacción social. El modelo admite reproducción simultánea mientras genera, con audio y video sincronizados, y el primer fotograma aparece en menos de 1 segundo tras la instrucción. Con la GPU al máximo, el costo de inferencia por segundo se reduce a 0.00025 dólares, es decir, 1/2000 del costo de Veo 3 y 1/560 del de Seedance. El modelo cuenta con 22 mil millones de parámetros, funciona de manera estable en una sola H100, e incluso en la tarjeta de inferencia RTX Pro 6000, de menor costo, mantiene una velocidad en tiempo real superior a 30 FPS.

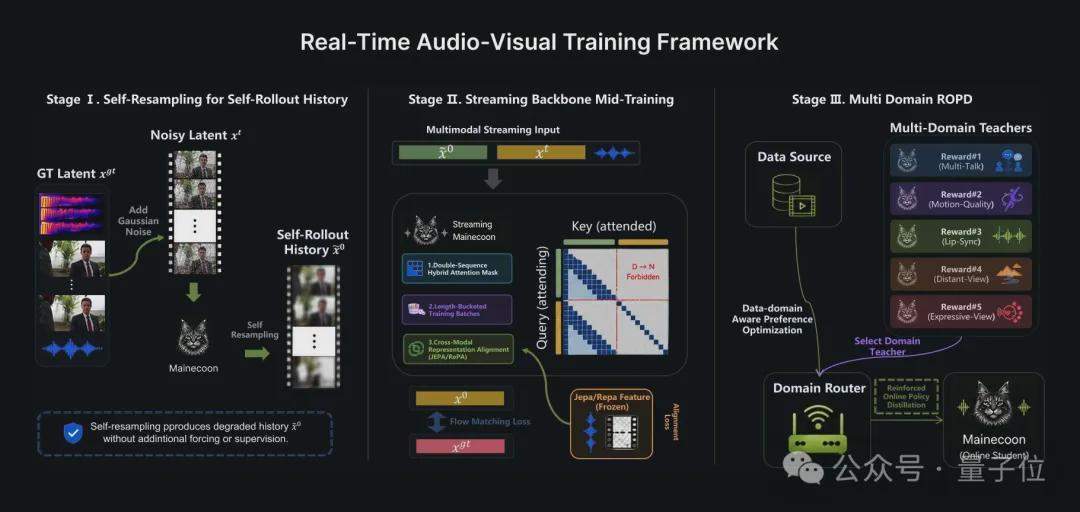
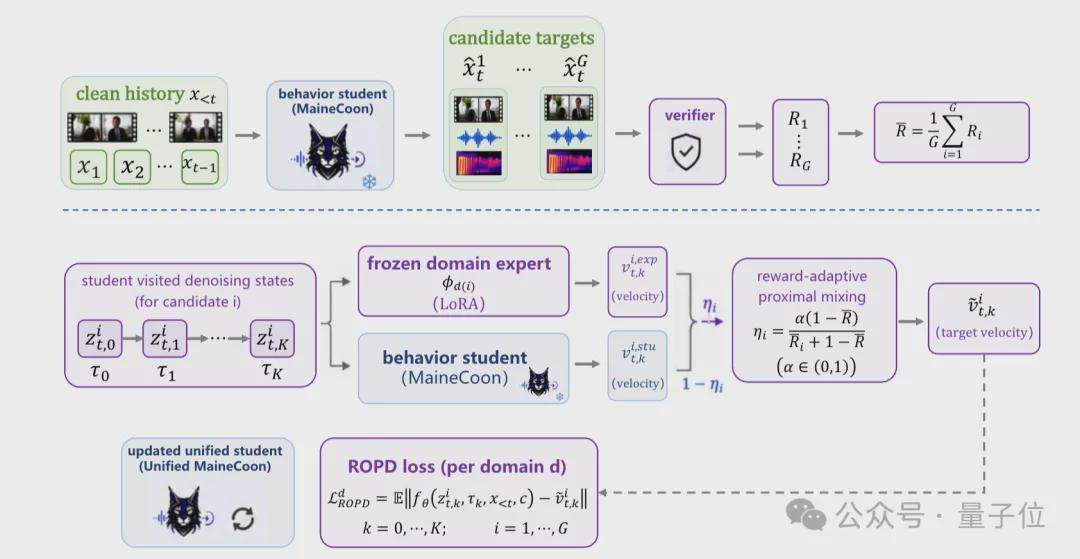
El equipo de Catnip detalla en su informe técnico la arquitectura de entrenamiento e inferencia de MaineCoon. El marco de entrenamiento se divide en tres fases: Auto-remuestreo (Self-Resampling) para resolver la brecha entre entrenamiento e inferencia; Alineación de Representaciones (Representation Alignment) que acelera la convergencia del entrenamiento conjunto de audio y video mediante un codificador visual V-JEPA 2 preentrenado congelado; y Optimización de Preferencias con Conciencia de Dominio (DPO) combinada con Destilación de Políticas en Línea Reforzada (ROPD), entrenando modelos expertos de preferencia específicos para diferentes escenarios sociales. Todo el modelo se entrenó en 64 GPU H100, con menos de 1 millón de datos y 10k horas de GPU.
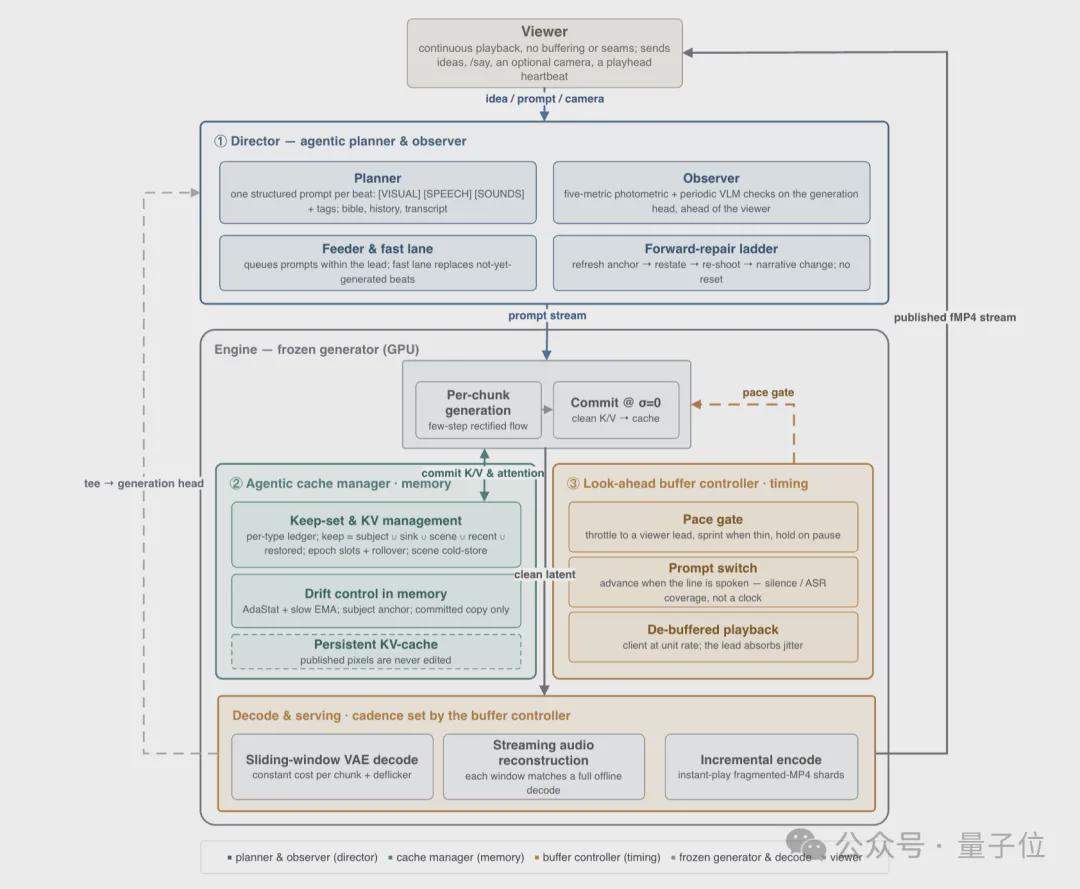
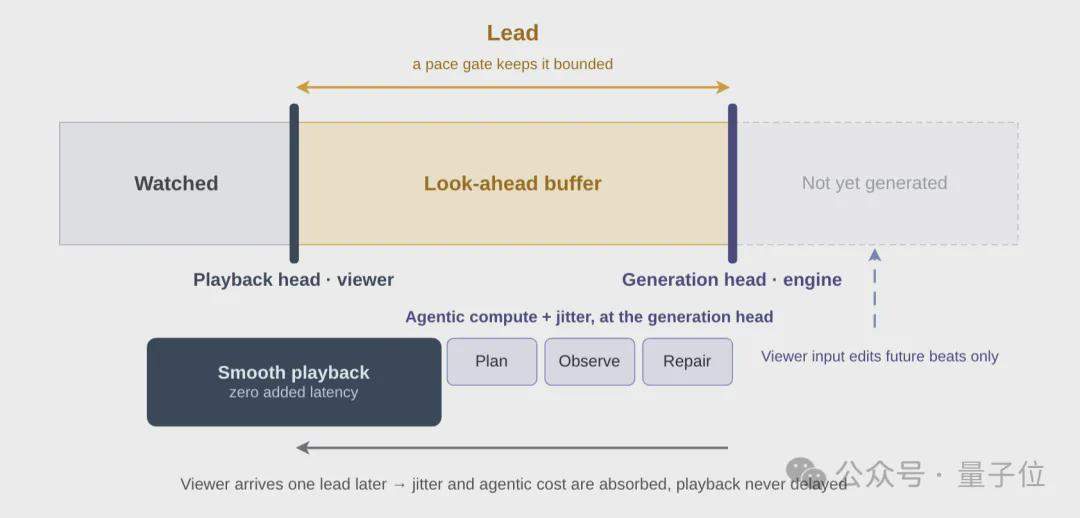
En el lado de la inferencia, se emplea un marco de inferencia Agéntico compuesto por tres controladores inteligentes independientes: Director, encargado de la narrativa y corrección de errores, que genera indicaciones estructuradas por compás mediante un planificador y monitorea la calidad de generación con un observador; Cache Manager, que gestiona las políticas de retención y eliminación de la caché KV, utilizando la apariencia de los personajes y los fotogramas de establecimiento de escenas como puntos de anclaje de memoria a largo plazo; y Buffer Controller, que controla el búfer de anticipación para equilibrar la capacidad de respuesta en tiempo real con la interacción.
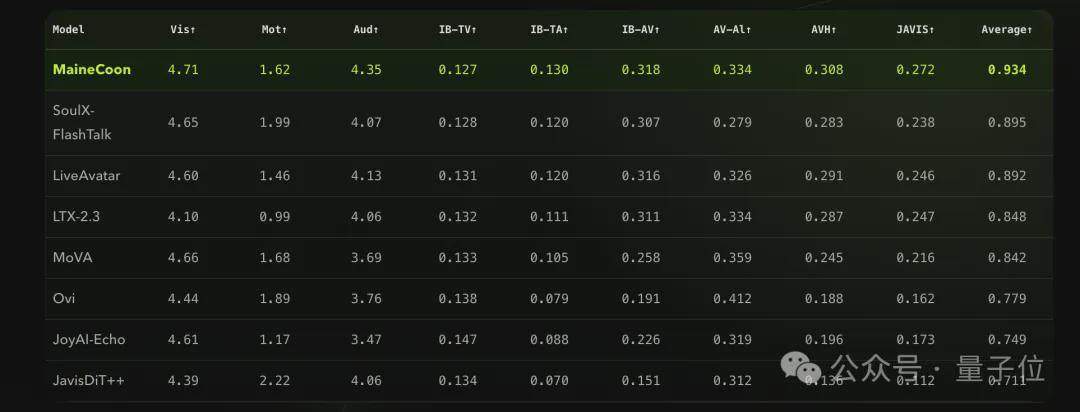
El equipo de Catnip también ha creado el primer punto de referencia especializado para videos cortos sociales, SocialVideo Bench, que abarca siete escenarios: discursos densos, interacción en pareja, canto musical, actuación emocional, baile, desafíos creativos y memes sociales. Las evaluaciones muestran que MaineCoon obtiene una puntuación general de 0.934, superando a siete modelos principales de generación de audio y video, como SoulX-FlashTalk (0.895).
El equipo de Catnip propone por primera vez el concepto de "modelo de mundo social", que consta de tres niveles: capa de percepción (lectura de emociones del usuario), capa de simulación (predicción de comportamientos sociales) y capa de renderizado (generación en tiempo real de audio y video). MaineCoon se considera un avance en la capa de renderizado. El equipo planea superar el modo de interacción semidúplex de los diálogos tradicionales de IA, logrando una interacción bidireccional en tiempo real, continua, entrelazada y multimodal al estilo humano, y promoviendo el modelo como una plataforma de contenido interactivo.
La fundadora del equipo, Yang Shurui, trabajó anteriormente en TikTok y PixVerse, donde lideró la implementación de productos de plantillas y efectos virales, y cuenta con experiencia emprendedora continua. El científico jefe, Xie Zeke, es profesor asistente en la Universidad de Ciencia y Tecnología de Hong Kong (Guangzhou), con una licenciatura en la Universidad de Ciencia y Tecnología de China y un doctorado en la Universidad de Tokio. Participó en investigaciones de vanguardia sobre modelos grandes en el Instituto de Investigación de Baidu y ha sido presidente de área en conferencias líderes de IA como NeurIPS, ICLR e ICML. El resto del equipo está compuesto principalmente por recién graduados.
El equipo de Catnip publicó previamente el informe técnico en la plataforma social X, atrayendo atención de múltiples partes, y la empresa oficial LTX también buscó activamente colaboración. El equipo reveló que, a principios de año, recibió financiación de ronda inicial de inversores como Sequoia y Mingshi.

Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com










