es.wedoany.com Noticia: El trabajo de inteligencia espacial multimodal Spatial-TTT, cuyo primer autor es el estudiante de doctorado de la Universidad Tsinghua Liu Fangfu, realizado en colaboración con múltiples investigadores, ha sido recientemente aceptado en la conferencia principal de visión por computadora ECCV 2026. Este trabajo se centra en resolver el problema de la inteligencia espacial en flujo continuo de los modelos multimodales grandes en el mundo físico real, es decir, cómo el modelo forma y actualiza continuamente la memoria espacial en un flujo de video en constante cambio, en lugar de tratar cada entrada como un segmento independiente.
Escenarios del mundo real, como la navegación de robots, la conducción autónoma y la realidad aumentada, requieren que el modelo tenga capacidades que van mucho más allá de la comprensión de imágenes estáticas. Los métodos tradicionales, al procesar flujos de video largos que duran decenas de minutos o incluso horas, carecen de un mecanismo efectivo de actualización de memoria en línea, lo que provoca una fragmentación de la comprensión espacial. La propuesta de Spatial-TTT surge precisamente para abordar este desafío, introduciendo el concepto de entrenamiento en tiempo de prueba (TTT) en el campo de la inteligencia espacial, permitiendo que el modelo actualice sus parámetros internos mientras observa el video durante el proceso de inferencia.
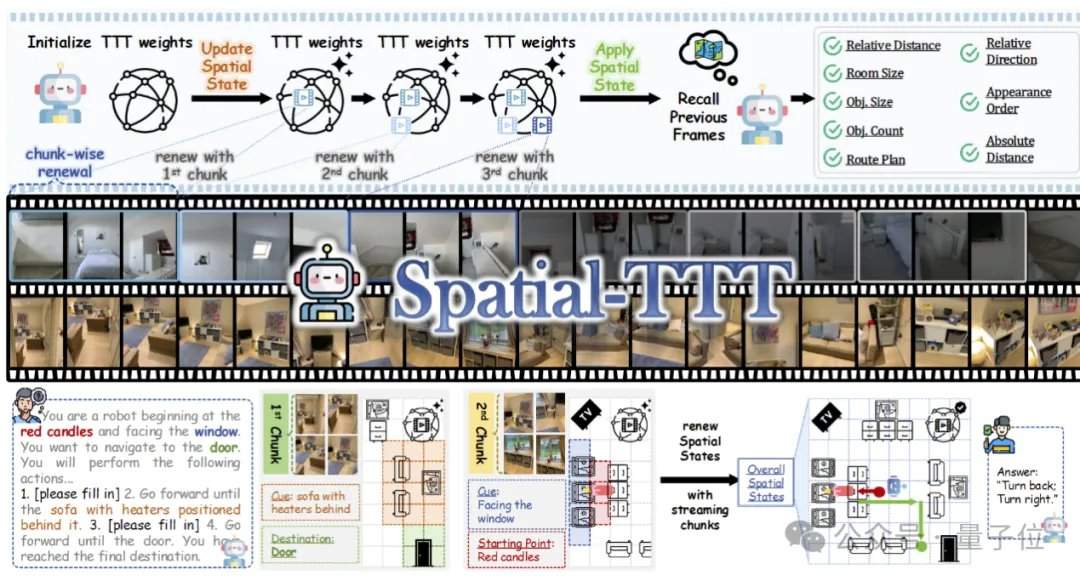
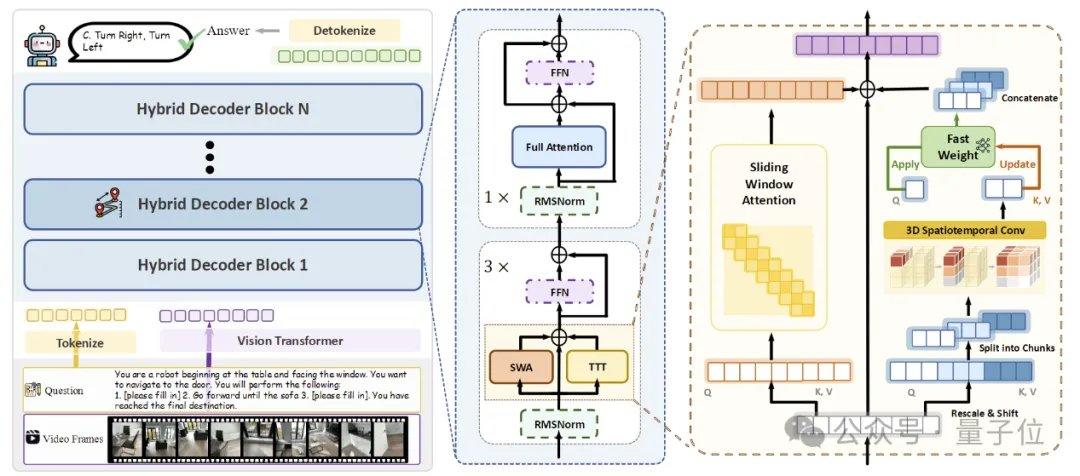
Para lograr una memoria espacial en flujo eficiente, el equipo de investigación propuso tres tecnologías clave. La primera es la arquitectura híbrida TTT, que intercala capas TTT y capas de anclaje de autoatención estándar en el decodificador en una proporción de 3:1; las primeras se encargan de escribir información de largo alcance en pesos rápidos, mientras que las segundas mantienen la capacidad de alineación multimodal y razonamiento semántico del modelo preentrenado. La segunda es el mecanismo de predicción espacial, que introduce convoluciones espacio-temporales 3D ligeras en la rama TTT, permitiendo que el modelo aprenda relaciones de predicción entre contextos espacio-temporales, mejorando la estabilidad de la actualización en línea. La tercera es la supervisión densa de descripciones de escenas, que construye datos de descripción de escenas que cubren el contexto global, categorías de objetos y relaciones espaciales, entrenando al modelo para pasar de "responder preguntas locales" a "mantener una memoria 3D global".
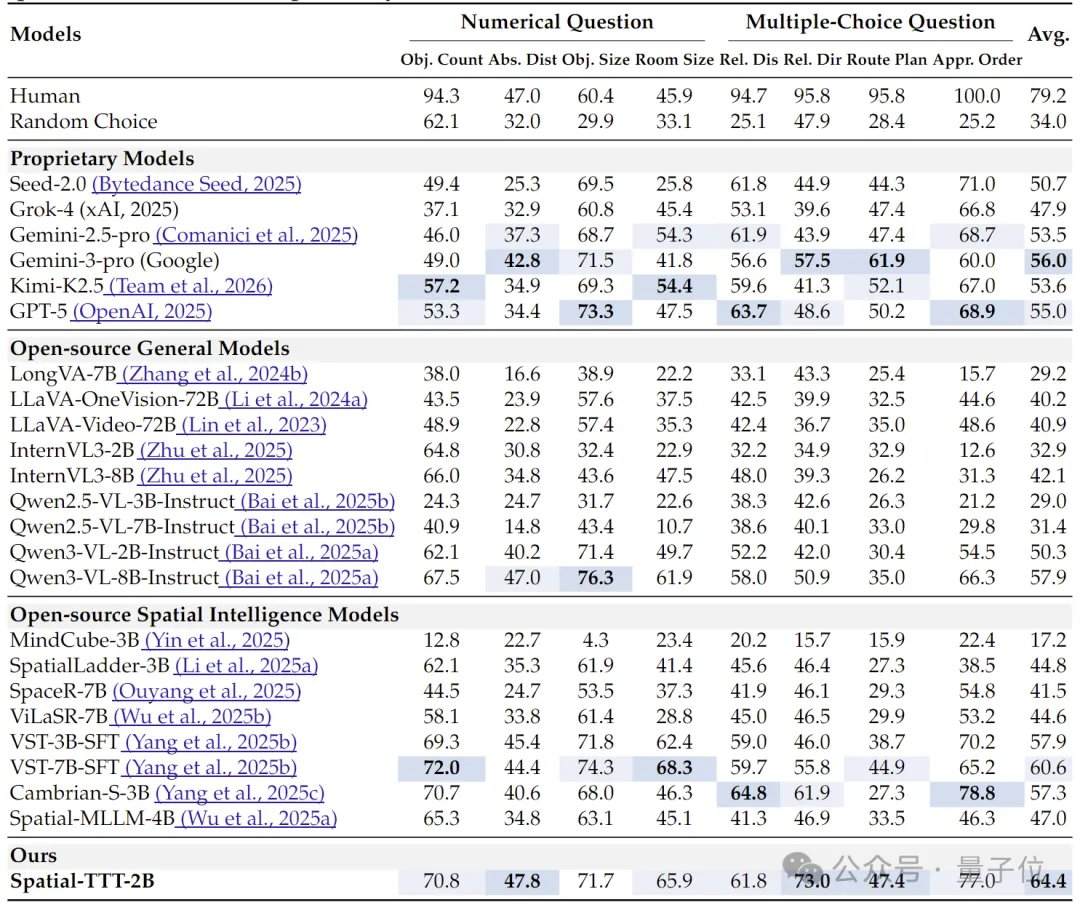
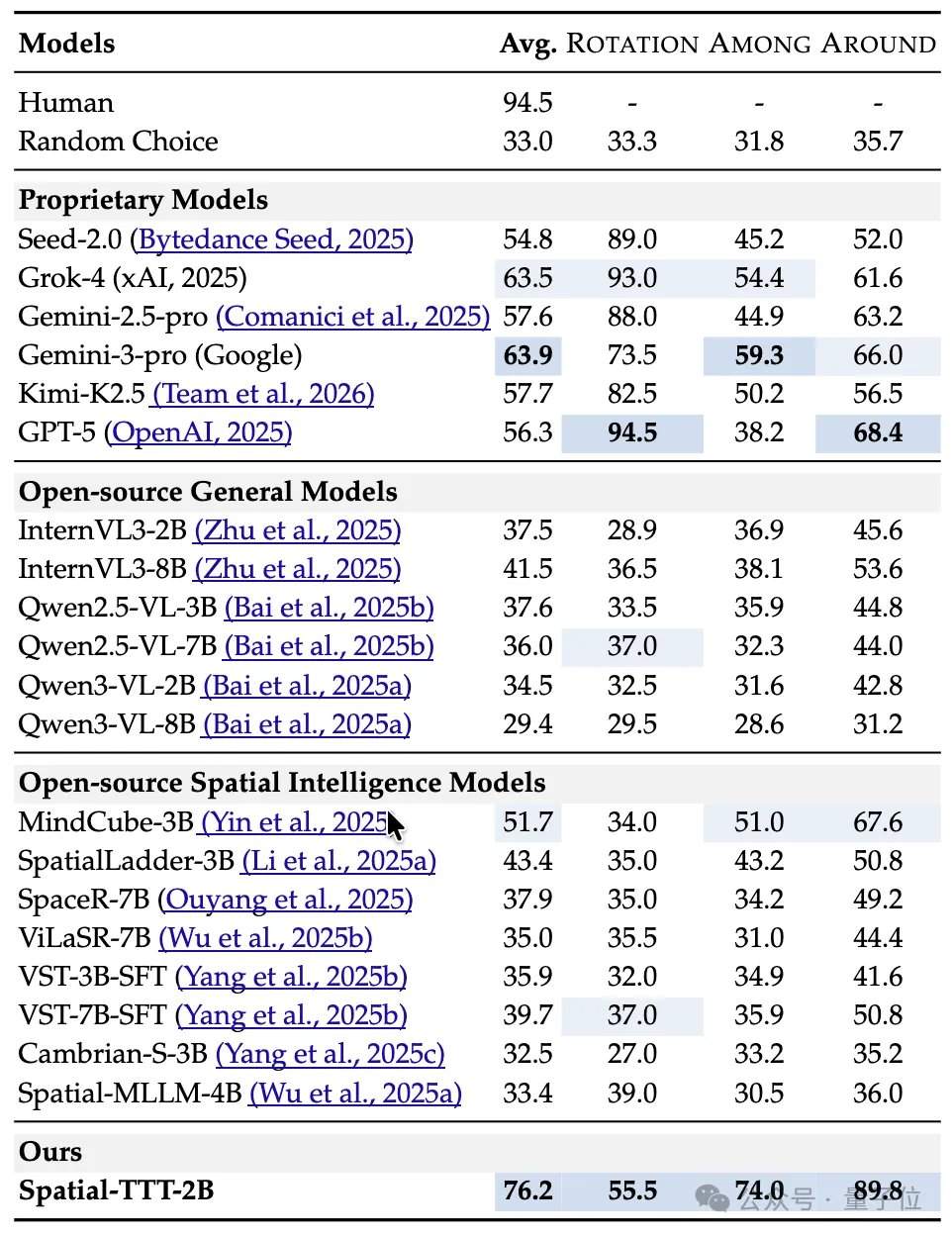
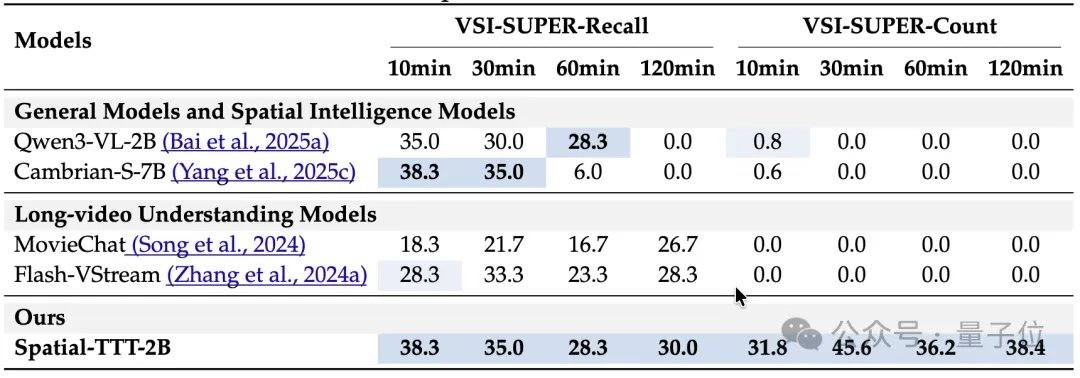
En cuanto a los resultados experimentales, Spatial-TTT, con solo 2B parámetros, muestra ventajas significativas en múltiples puntos de referencia especializados de inteligencia espacial. En VSI-Bench, su puntuación promedio alcanzó 64.4, superando a modelos cerrados como GPT-5 y Gemini-3-pro. En el punto de referencia MindCube-Tiny, que pone a prueba el razonamiento espacial de grano fino multivista, Spatial-TTT logró una precisión del 76.2%, superando a Gemini-3-pro (63.9%) en 12 puntos porcentuales y al modelo espacial de código abierto representativo MindCube-3B (51.7%) en casi 25 puntos porcentuales. En las tareas de la serie VSI-SUPER, que evalúan la memoria a largo plazo, el modelo puede manejar de manera estable videos en flujo de hasta 120 minutos. En la tarea VSI-SUPER-Count, las puntuaciones de Spatial-TTT en videos de 10, 30, 60 y 120 minutos alcanzaron 31.8, 45.6, 36.2 y 38.4, respectivamente.
El análisis de eficiencia muestra que, en una configuración de entrada de 1024 fotogramas, el uso máximo de memoria de video de Spatial-TTT-2B es de 11.9 GB, con una cantidad teórica de cálculo de 799.4 TFLOPs, logrando un ahorro de más del 40% en memoria y recursos computacionales en comparación con los modelos de referencia líderes de la industria. Los experimentos de ablación confirman además que la mejora en el rendimiento proviene del efecto sinérgico entre la arquitectura híbrida, el mecanismo de predicción espacial y las señales de supervisión densas. Específicamente: al eliminar el mecanismo de predicción espacial, la puntuación promedio en VSI-Bench bajó de 64.4 a 62.1; al eliminar la supervisión densa de descripciones de escenas, bajó a 61.3; si se elimina por completo la arquitectura híbrida y se usa solo la estructura TTT pura, la puntuación promedio cayó directamente a 53.9.
Esta investigación, aceptada en ECCV 2026, proporciona una nueva vía técnica para los sistemas de inteligencia artificial física que requieren un funcionamiento continuo a largo plazo. Al permitir que el modelo acumule, corrija y utilice información espacial de manera continua, los agentes inteligentes del futuro ya no se enfrentarán a imágenes fragmentadas fotograma a fotograma, sino que podrán construir un modelo de mundo interno que sea continuo, comprensible y en el que puedan actuar.
Enlace al artículo: https://arxiv.org/pdf/2603.12255
Página del proyecto: https://liuff19.github.io/Spatial-TTT/
GitHub: https://github.com/THU-SI/Spatial-TTT/
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com