es.wedoany.com Noticia: Investigadores del Laboratorio de Inteligencia Artificial de Shanghái (Shanghai Artificial Intelligence Laboratory) han propuesto un nuevo paradigma denominado "Self-Harness", que permite a los agentes basados en modelos de lenguaje de gran escala (LLM) mejorar sistemáticamente sus propias reglas de funcionamiento sin depender de ingenieros humanos ni de modelos externos más potentes.
El rendimiento de los agentes basados en LLM no solo depende del modelo base, sino también de su marco, que incluye indicaciones del sistema, herramientas, memoria, reglas de verificación, estrategias de ejecución, lógica de orquestación y procedimientos de recuperación de fallos. Las fallas comunes de los agentes suelen originarse en el marco y no en el modelo en sí. Por ejemplo, un agente podría informar éxito sin verificar la respuesta del modelo, o reintentar repetidamente una operación fallida. SWE-agent, Claude Code, Codex y OpenHands son ejemplos populares de marcos.
Hangfan Zhang, primer autor del artículo sobre Self-Harness, señaló que el verdadero cuello de botella de la ingeniería manual de marcos radica en la dependencia de depuraciones ad hoc, en lugar de bucles de retroalimentación sistemáticos. Muchas ediciones se basan en la intuición o en unos pocos casos de fallo, lo que dificulta seguir el ritmo de la rápida evolución de los LLM. El paradigma Self-Harness permite que los agentes basados en LLM logren una autoevolución mediante un ciclo iterativo de tres fases.
El ciclo comienza con la fase de detección de debilidades: el agente ejecuta tareas para generar trayectorias de ejecución, clasifica las trayectorias fallidas y detecta patrones de fallo específicos del modelo. Le sigue la fase de propuesta de marco: el agente utiliza un rol de "proponente" para generar un conjunto diverso y mínimo de modificaciones al marco, cada una dirigida a un mecanismo de fallo específico. Finalmente, la fase de validación de propuestas: el sistema evalúa las modificaciones candidatas mediante pruebas de regresión, y solo se adoptan si la edición no provoca una degradación en el rendimiento de las tareas retenidas. Si varios candidatos pasan las pruebas, se fusionan en la siguiente versión del marco.
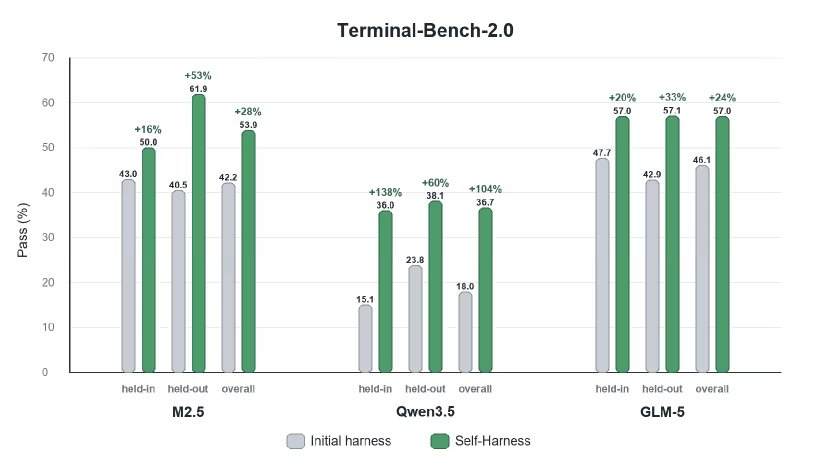
Los investigadores evaluaron Self-Harness en el punto de referencia Terminal-Bench-2.0, que prueba la ejecución basada en herramientas, incluyendo la gestión de artefactos, el uso de comandos, el comportamiento de verificación y la recuperación de errores de ejecución. Aplicaron Self-Harness a MiniMax M2.5, Qwen3.5-35B-A3B y GLM-5. Los resultados cuantitativos mostraron que los agentes mejoraron su rendimiento mediante ediciones automatizadas del marco, con mejoras relativas que oscilaron entre el 33% y el 60% en diferentes modelos para las tareas retenidas.
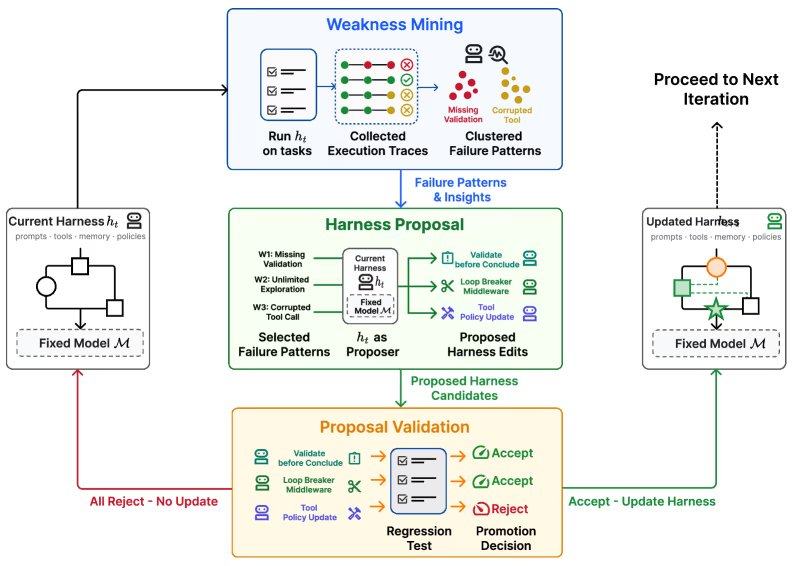
Los experimentos demostraron que Self-Harness introdujo cambios específicos que reflejan los problemas recurrentes de cada modelo durante la ejecución. Por ejemplo, MiniMax M2.5, bajo el marco base, exploraba sin cesar configuraciones de conjuntos de datos hasta agotar el tiempo de espera; el sistema lo corrigió escribiendo una regla de "interrupción de bucle" (deteniéndose después de 50 llamadas a herramientas y redirigiendo el método) y añadiendo un requisito para crear una versión inicial lo antes posible. Qwen-3.5 repetía el mismo comando tras encontrar un error de sobrescritura de archivos; el sistema introdujo una disciplina estricta de reintentos (prohibiendo la repetición completa de comandos) y un mecanismo para recrear inmediatamente los artefactos perdidos tras un error de archivo. GLM-5 tenía dificultades para mantener los cambios de entorno entre comandos; su marco autogenerado introdujo reglas como la persistencia de la variable PATH, la limitación de la computación externa y la reparación de cualquier verificación de integridad fallida antes de finalizar la ejecución.
Zhang señaló que la ingeniería automatizada de marcos requiere un costo computacional para la generación repetida, la evaluación paralela y las pruebas de regresión. El sistema también depende de la precisión del pipeline de evaluación, basándose en validadores estrictos y deterministas en los experimentos. Considera que los objetivos de despliegue óptimos son áreas como la codificación, la automatización de flujos de trabajo internos y los pipelines de datos de DevOps, donde los fallos son medibles y el ensayo y error es relativamente seguro. En cambio, áreas como las decisiones médicas, la infraestructura de seguridad crítica o las decisiones legales, donde la evaluación es subjetiva y costosa, deben evitar la automatización completa. A medida que aumenten las capacidades de los modelos base, los marcos se expandirán hacia afuera, conectando entornos externos más ricos. El rol del ingeniero pasará de parchear manualmente indicaciones o llamadas a herramientas individuales, a diseñar sistemas de retroalimentación que permitan la mejora de los agentes.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com