es.wedoany.com Noticia: La pila de software de inferencia de NVIDIA, en su plataforma Blackwell, ha reducido el costo por token del modelo DeepSeek V4 hasta en un quinto en un mes. A medida que las empresas pasan de pilotos de IA a fábricas de IA de producción, las decisiones de infraestructura han pasado de centrarse en las especificaciones máximas de los chips al costo por token, es decir, cuántos tokens útiles se producen por dólar y por vatio de energía, cumpliendo con los objetivos de latencia. La pila de software de inferencia de NVIDIA, diseñada conjuntamente con las GPU, CPU, redes y sistemas de NVIDIA, y mejorada a través de un amplio ecosistema de código abierto, continúa mejorando el rendimiento del hardware.
Empresas líderes y proveedores de inferencia ya están experimentando el valor añadido de la pila de software de inferencia de NVIDIA en Blackwell. Baseten utiliza la biblioteca de código abierto NVIDIA TensorRT-LLM en GPU Blackwell para ofrecer el servicio DeepSeek V4 Pro, adecuado para cargas de trabajo de inferencia, codificación y contexto largo, logrando un aumento de hasta el 50% en la salida de tokens por segundo mediante optimizaciones de tiempo de ejecución patentadas. Cognition utiliza el marco de inferencia NVIDIA Dynamo para gestionar las GPU de inferencia, proporcionando a su equipo una ruta lista para escalar cargas de trabajo de aprendizaje por refuerzo sin necesidad de construir infraestructura desde cero. Deep Infra utiliza la pila de software de inferencia de NVIDIA para ejecutar modelos de código abierto de vanguardia, incluido DeepSeek V4, con alto rendimiento en Blackwell desde el primer día. Together AI utiliza NVIDIA TensorRT-LLM en Blackwell para ayudar a Cursor a acelerar el camino desde la optimización del modelo hasta el endpoint de producción, respaldando su experiencia de codificación en tiempo real.
Las cargas de trabajo tradicionales de web, búsqueda y software como servicio son relativamente predecibles, a diferencia de la IA agente. Los agentes pueden razonar, planificar, invocar herramientas, iniciar subagentes especializados y gestionar grandes cantidades de contexto en flujos de trabajo de múltiples rondas, transformando una sola solicitud en un problema de computación distribuida que puede involucrar cientos de subagentes, miles de tareas y múltiples modelos de lenguaje grandes, ejecutándose en GPU, CPU, DPU y sistemas de almacenamiento. La pila de software determina si esta complejidad se traduce en potencia de cómputo desperdiciada o en un menor costo por token.
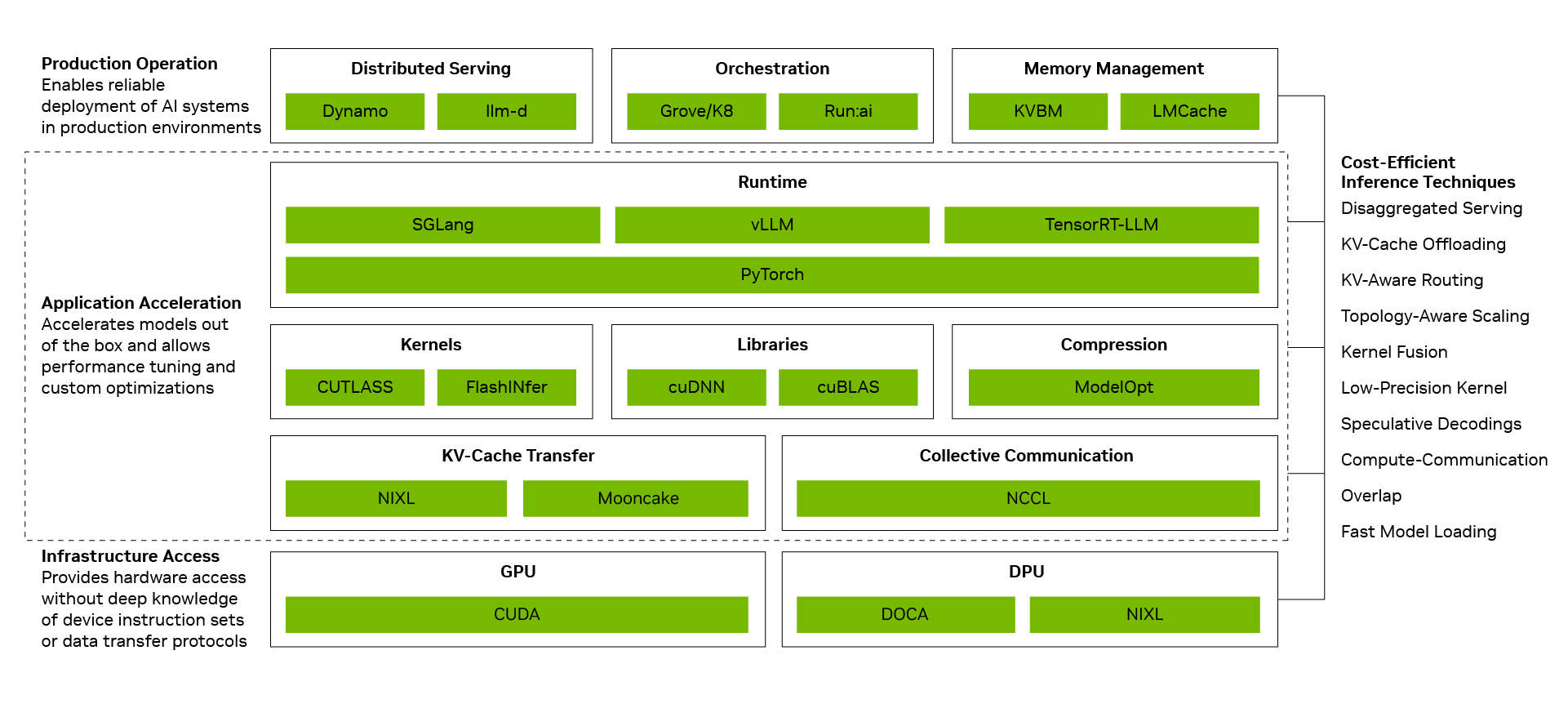
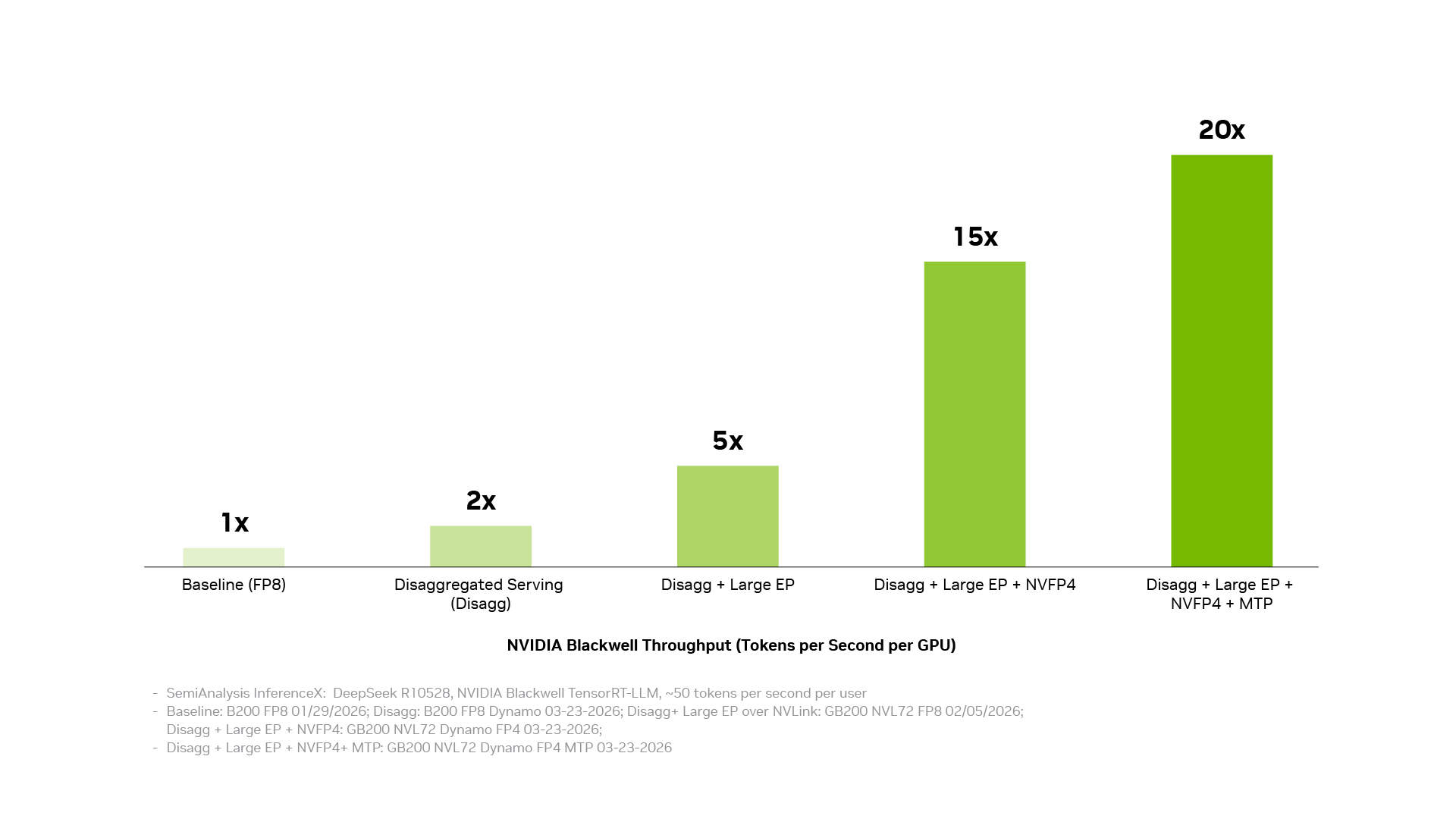
Un menor costo por token proviene de convertir optimizaciones individuales en rendimiento a nivel de sistema. La pila de software de inferencia de NVIDIA logra esto conectando tres capas: la capa de operaciones de producción coordina servicios distribuidos, orquestación, escalado automático y gestión de memoria; la capa de aceleración de aplicaciones ejecuta modelos con alto rendimiento y ofrece a los desarrolladores espacio para ajustes y personalización; la capa de acceso a infraestructura expone las capacidades de GPU, redes, memoria y sistemas de NVIDIA. Cuando estas capas trabajan juntas como un sistema, las optimizaciones individuales se acumulan. El desacoplamiento de servicios, el paralelismo de expertos a gran escala basado en la tecnología de interconexión NVIDIA NVLink, la precisión NVFP4 y la predicción de múltiples tokens generan cada uno ganancias significativas; combinarlos puede aumentar el rendimiento hasta 20 veces.
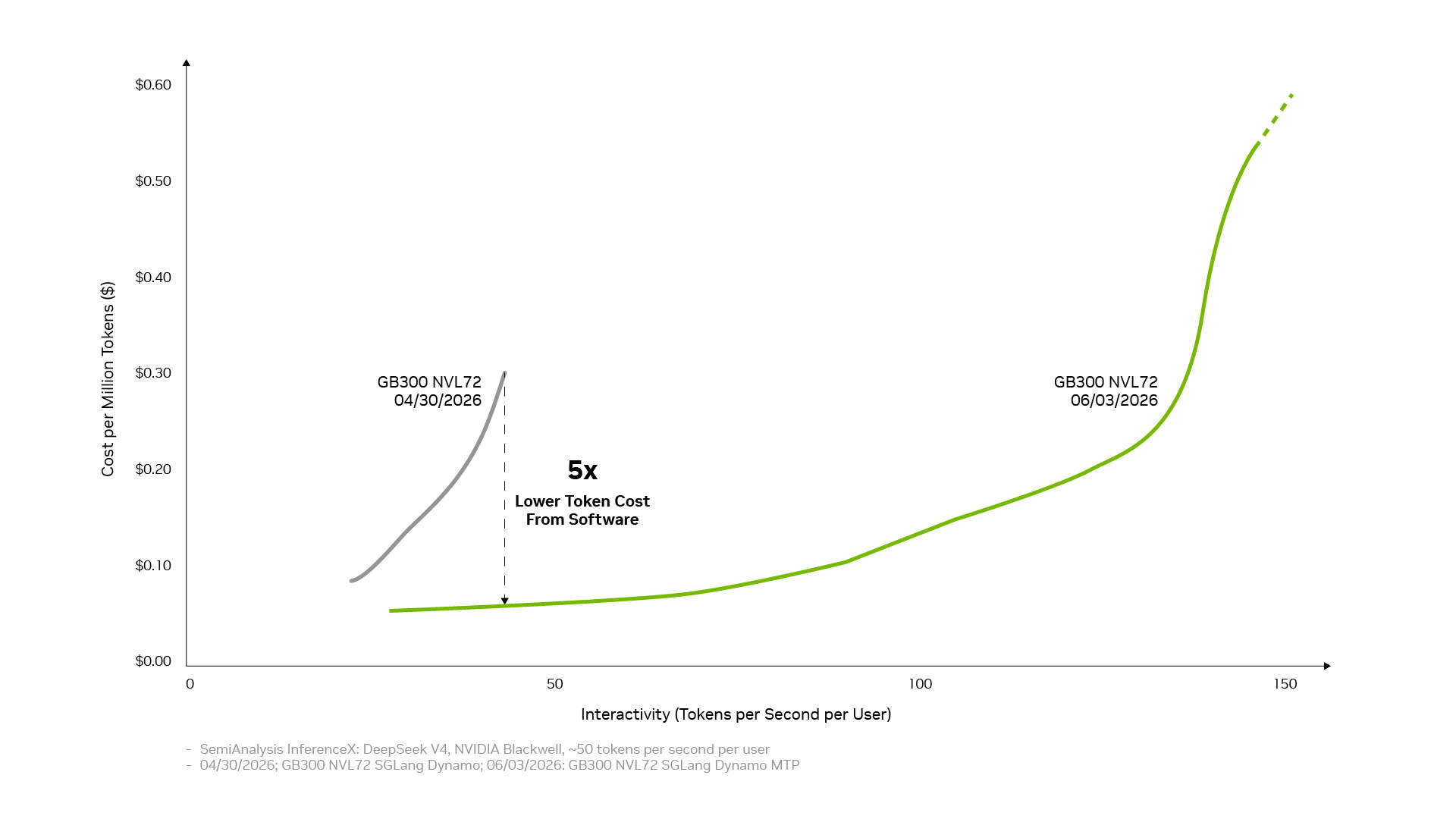
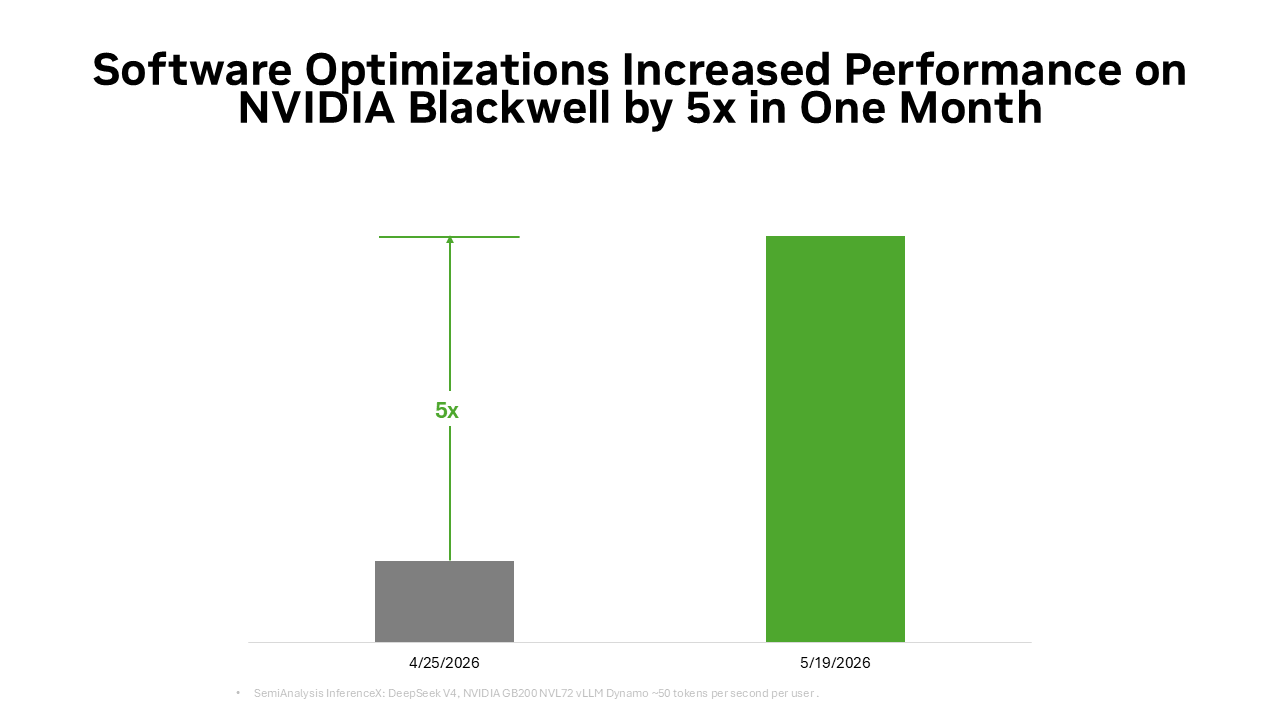
Esta misma base de pila completa también se amplifica a través del ecosistema de código abierto. Muchos de los marcos y proyectos de inferencia de IA de código abierto más utilizados hoy en día están construidos de forma nativa sobre NVIDIA CUDA. PyTorch es un ejemplo típico; lanzado en 2016, es compatible de forma nativa con CUDA y ha coevolucionado con la arquitectura NVIDIA. Cuando tecnologías innovadoras como la decodificación especulativa de DFlash o FastVideo se implementan en PyTorch, pueden ejecutarse inmediatamente en NVIDIA. Cuando se lanzan modelos de código abierto de vanguardia como DeepSeek V4, marcos de inferencia líderes como vLLM y SGLang pueden proporcionar soluciones de implementación para la arquitectura NVIDIA Blackwell desde el primer día. Esta es también la razón por la que el rendimiento de DeepSeek V4 en Blackwell ha mejorado hasta 5 veces en un mes a través de los marcos vLLM y SGLang, reduciendo el costo por token a aproximadamente una quinta parte.
Este es el volante de código abierto: cada vez más desarrolladores optimizan las rutas de inferencia basadas en CUDA, más implementaciones de producción retroalimentan el ecosistema, y cada mejora de software aumenta la cantidad de tokens generados, al tiempo que reduce el costo por token.