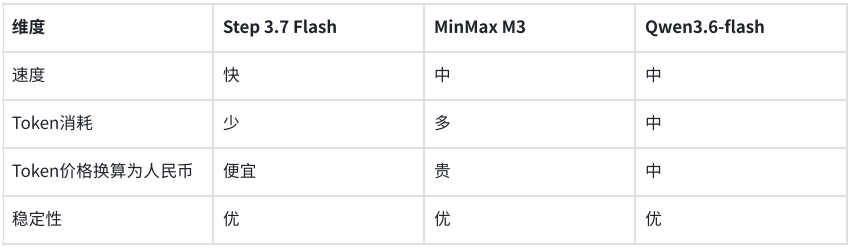
es.wedoany.com Noticia: En el contexto en que los modelos multimodales pasan de la demostración a la implementación en producción, los modelos Step 3.7 Flash, Qwen3.6-flash y MiniMax M3 fueron sometidos a pruebas en escenarios de desarrollo y negocio. Una evaluación comparativa centrada en dos tareas —reconocimiento de diagramas de flujo y análisis de documentos— mostró que los tres modelos ofrecen una calidad estable en comprensión visual y salida estructurada, aunque presentan diferencias en velocidad de respuesta y consumo de tokens.
La evaluación, realizada en torno a tres dimensiones —calidad, velocidad y costo—, seleccionó dos tipos de escenarios industriales: primero, la restauración de la lógica de negocio a partir de diagramas de flujo del sistema durante el desarrollo de agentes; segundo, la extracción estructurada de información de facturas mediante llamadas API en sistemas de negocio. Las pruebas indicaron que ninguno de los tres modelos cometió errores graves de reconocimiento en ninguna de las dos tareas, y la usabilidad de las salidas fue alta.
En el escenario de comprensión de diagramas de flujo, el modelo debía extraer con precisión 10 pasos de la lógica de negocio a partir de un diagrama de flujo de autenticación de inicio de sesión de un miniprograma de WeChat. Step 3.7 Flash identificó correctamente los 10 pasos, y cada paso coincidió completamente con la lógica del diagrama original. MiniMax M3 también generó 10 pasos con la lógica correcta. Qwen3.6-flash fusionó los pasos 3 y 4, generando 9 pasos, pero la lógica general fue correcta. Con una calidad de salida comparable, Step 3.7 Flash mostró la velocidad de respuesta más rápida y el menor consumo de tokens.
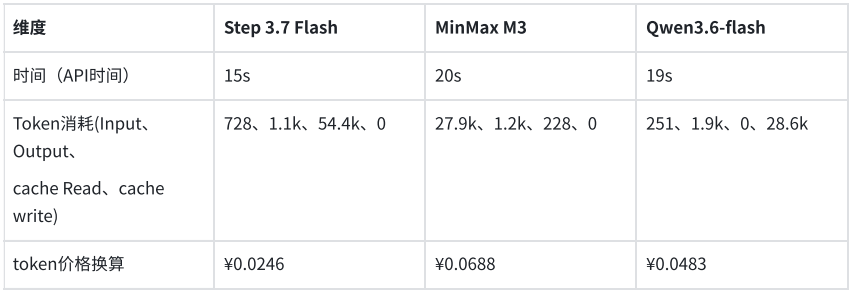
En otra prueba orientada a sistemas de negocio, el modelo debía extraer los campos clave de una factura electrónica y generarlos en una estructura JSON predefinida. Los tres modelos identificaron y estructuraron con precisión la información requerida. Step 3.7 Flash completó la tarea en 5.6 segundos, consumiendo 1409 tokens; MiniMax M3 tardó 6.1 segundos, consumiendo 2216 tokens; Qwen3.6-flash tardó 7.38 segundos, consumiendo 2008 tokens. El costo de extracción estructurada por cada factura fue inferior a 1 centavo.
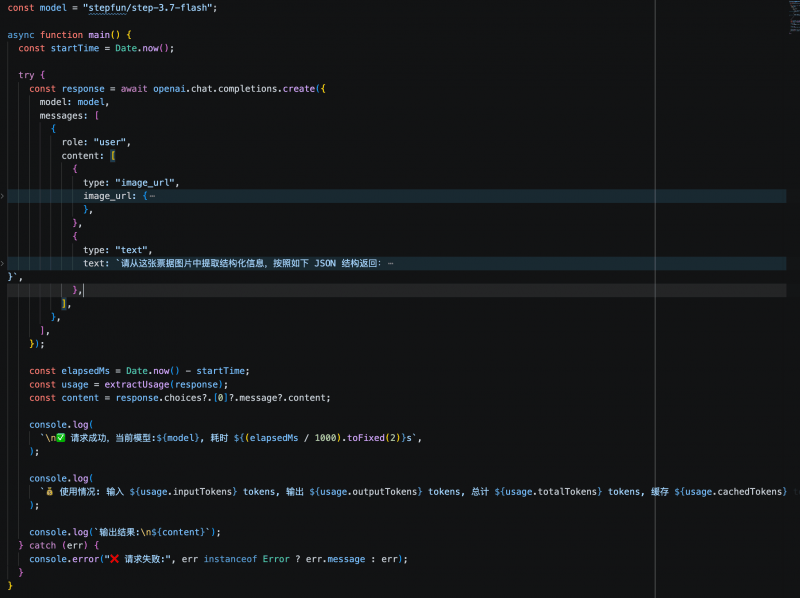

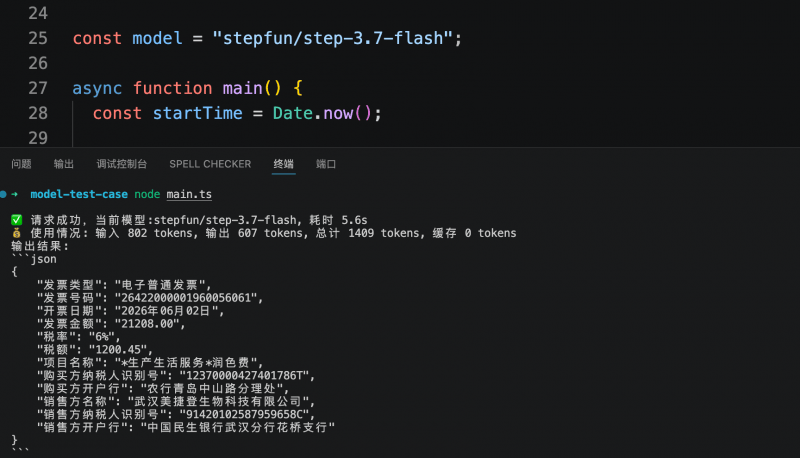
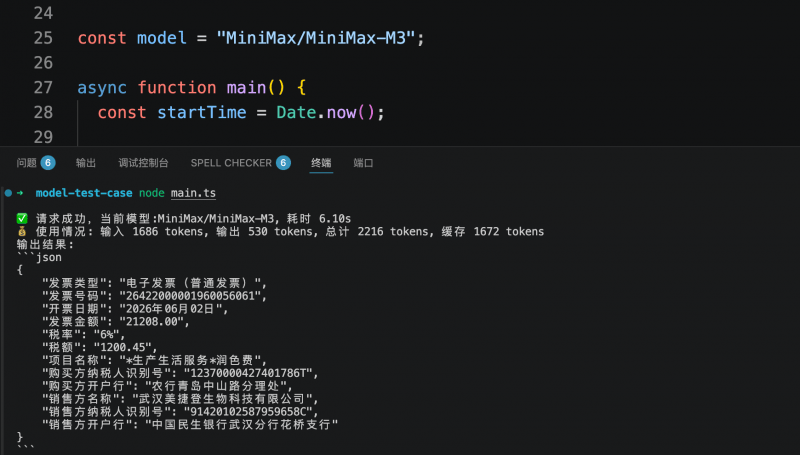
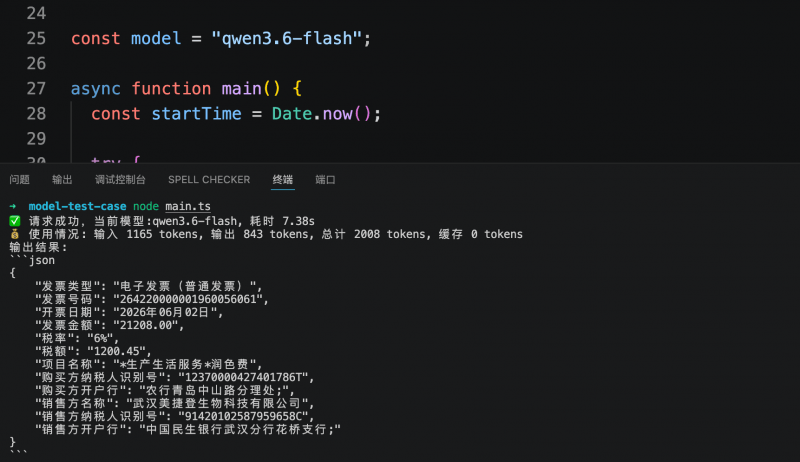
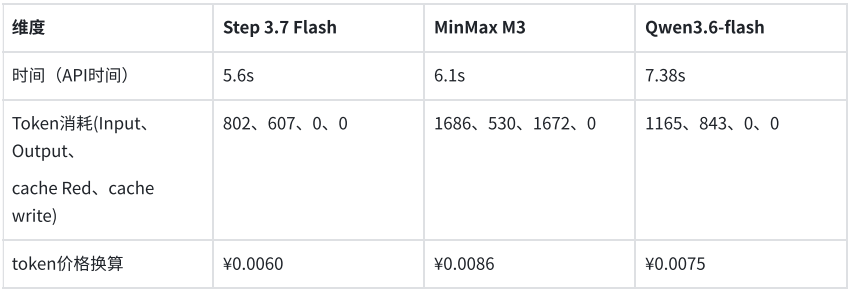
En conjunto, las dos pruebas mostraron que la estabilidad de calidad en comprensión visual y salida estructurada de los tres modelos cumple con los requisitos iniciales de producción, sin errores de extracción. Para escenarios de agentes o API de negocio con llamadas frecuentes, la latencia de respuesta y el consumo de tokens se convierten en indicadores clave de diferenciación. En esta comparación, Step 3.7 Flash, manteniendo la misma calidad de salida, ofrece una velocidad de respuesta más rápida y un costo menor, lo que lo hace más adecuado para ser priorizado en pruebas en entornos de producción.