es.wedoany.com Noticia: A medida que la escala de densidad de transistores se ralentiza, el empaquetado avanzado se ha convertido en la principal vía de expansión. Sin embargo, los aceleradores de inteligencia artificial son voluminosos y requieren velocidades de interconexión extremadamente altas, lo que lleva al propio empaquetado a sus límites. Los interpositores circulares limitan el tamaño del empaquetado y la utilización de la oblea. La tecnología HBM4E duplica el número de E/S al aumentar la velocidad, mientras que los empaquetados de múltiples kilovatios hacen que las arquitecturas de refrigeración tradicionales sean insostenibles.
ECTC es el principal evento de tecnología de empaquetado de la industria. Los contenidos presentados este año están estrechamente relacionados con productos comerciales próximos a lanzarse. Intel describió la integración de EMIB-T, la escala del tamaño del empaquetado y su hoja de ruta futura. Marvell demostró cómo eliminar la lógica de interfaz del acelerador mediante HBM personalizado, acortando al mismo tiempo el cableado del empaquetado. TSMC y Microsoft integraron refrigerante directamente en el silicio, mientras que Marvell y Lightmatter integraron interconexiones ópticas en el empaquetado.
Este resumen cubre las tecnologías de ECTC 2026 con mayor probabilidad de dar forma a las soluciones de aceleradores de IA en los próximos años.
Intel EMIB-T
Intel es el ponente corporativo más grande en la feria ECTC. Su enfoque principal es EMIB-T. Se trata de la próxima generación de chips EMIB que utiliza tecnología de silicio a través de vías (TSV). Tras el lanzamiento inicial, Intel perfeccionó la arquitectura y la hoja de ruta, incluyendo un paso de micro-bump más pequeño, tamaños de empaquetado más grandes y funcionalidad de puente. Su demostración indica que EMIB-T está destinado a aplicarse en la TPU v9 de Google y es la alternativa más fiable a la plataforma CoWoS de TSMC en el ámbito de los aceleradores de IA de empaquetado grande.
Chip de prueba de extensión EMIB-T, con contenido de silicio del doble de la retícula. Las imágenes de microscopía electrónica de barrido en vista superior muestran pasos de micro-bump de 110, 55 y 36 micrómetros.

Intel ha verificado la tecnología EMIB-T en chips empaquetados con silicio del doble del tamaño de la retícula, con un paso de micro-bump de 36/35 micrómetros. En comparación con el paso de 45 micrómetros utilizado en el empaquetado de Granite Rapids, la densidad de micro-bumps ha aumentado un 65%. Granite Rapids-AP es un empaquetado grande, que mide 70 mm × 105 mm, con un área ligeramente inferior a 9 retículas. Actualmente, la verificación para el paso de 36/35 micrómetros se está expandiendo a empaquetados de silicio de 4.5 veces el tamaño de la retícula, con el objetivo de completar la certificación a finales de 2026.

El siguiente paso en la reducción del paso también está en marcha; Intel está probando un paso de micro-bump de 25 µm, basado en un chip compuesto por dos chips de silicio de 1 retícula conectados mediante un único puente EMIB-T de 3 mm × 18 mm.
Reducir aún más el tamaño será más difícil. Por debajo de 25 µm, el volumen de soldadura en cada bola de soldadura se vuelve muy pequeño. La probabilidad de cortocircuitos, circuitos abiertos y pérdidas de rendimiento durante el ensamblaje aumenta significativamente. EMIB-T puede seguir reduciéndose, pero el factor limitante se desplaza de la densidad de cableado del puente a la formación de bolas de soldadura, la precisión de la colocación y el rendimiento del ensamblaje.
Intel también mostró los límites de tamaño del empaquetado EMIB-T. Aunque es posible lograr empaquetados de tamaño de panel completo, Intel ha establecido como objetivo práctico los empaquetados de cuarto de panel. Presentaron una muestra de prueba de 240 mm × 240 mm, con un área equivalente a aproximadamente 67 máscaras de litografía. Sin embargo, las muestras en el stand mostraban una deformación significativa. A este tamaño, el puente es solo una parte del problema. El manejo del sustrato, la deformación, la precisión de la superposición y el patrón a nivel de panel se convierten en factores limitantes principales. Intel también está evaluando tecnologías de litografía avanzada para garantizar una precisión de superposición suficientemente alta en estos sustratos grandes a tamaños de cuarto de panel o incluso de panel completo.
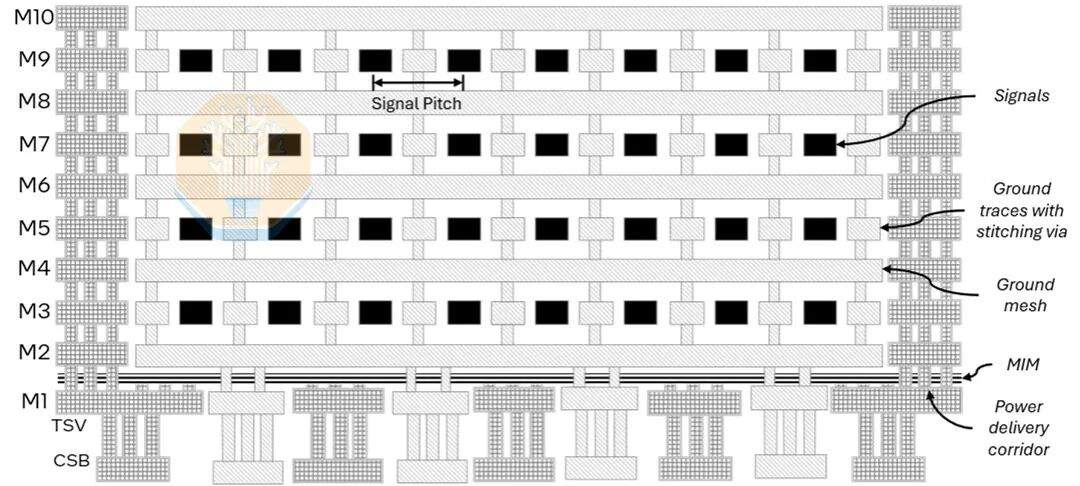
Aunque el paso de micro-bump y el tamaño del empaquetado son importantes, el circuito puente es igualmente crucial. EMIB-T es mucho más complejo que el EMIB utilizado en los productos actuales. Añade TSV, más capas metálicas, una malla de alimentación y una capa de condensador MIM, lo que permite que el circuito puente transmita simultáneamente señales de alta densidad y alimentación vertical. Intel mostró una imagen de sección transversal que contiene 10 capas metálicas (incluyendo 4 capas de cableado) y un condensador MIM entre M1 y M2. Intel destacó sus mejoras para HBM4E.
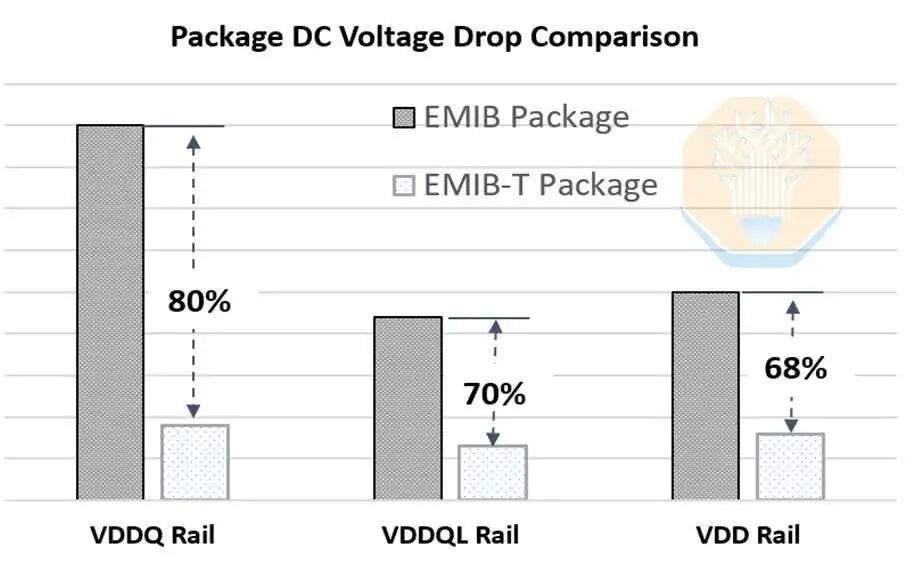
La "T" en EMIB-T significa TSV (silicio a través de vías). Su función es la alimentación eléctrica. En el EMIB tradicional, la alimentación en las áreas no puente se transmite verticalmente a través del sustrato, mientras que la alimentación cerca del área puente debe difundirse lateralmente hacia el cableado del empaquetado y del chip. Al utilizar TSV en el área puente, la alimentación puede transmitirse directamente a través de esta, acortando significativamente la trayectoria de la corriente. Intel afirma que el uso de estos TSV puede reducir la caída de tensión en corriente continua entre un 68% y un 80%.
La dificultad de HBM4E radica en que la interconexión debe aumentar simultáneamente la densidad de señal y la capacidad de alimentación. HBM4 tiene el doble de pines que HBM3, y la PHY requiere rieles de alimentación adicionales, como VDDQ y VDDQL. Estos rieles de alimentación ocupan parte del espacio de cableado de señal, aumentando así la densidad de señal en el espacio restante.
Para solucionar este problema, Intel no utiliza el mismo método de cableado para todos los canales HBM. Coloca las rutas de señal más largas en capas con cableado más sencillo. En la capa M9, solo aproximadamente el 28% de la longitud del canal más largo atraviesa el área de cableado más denso, mientras que en capas inferiores como M3, esta proporción aumenta a aproximadamente el 84%, pero estos canales son más cortos. Esto evita que la diafonía y la pérdida de inserción sean causadas principalmente por las áreas de peor cableado.
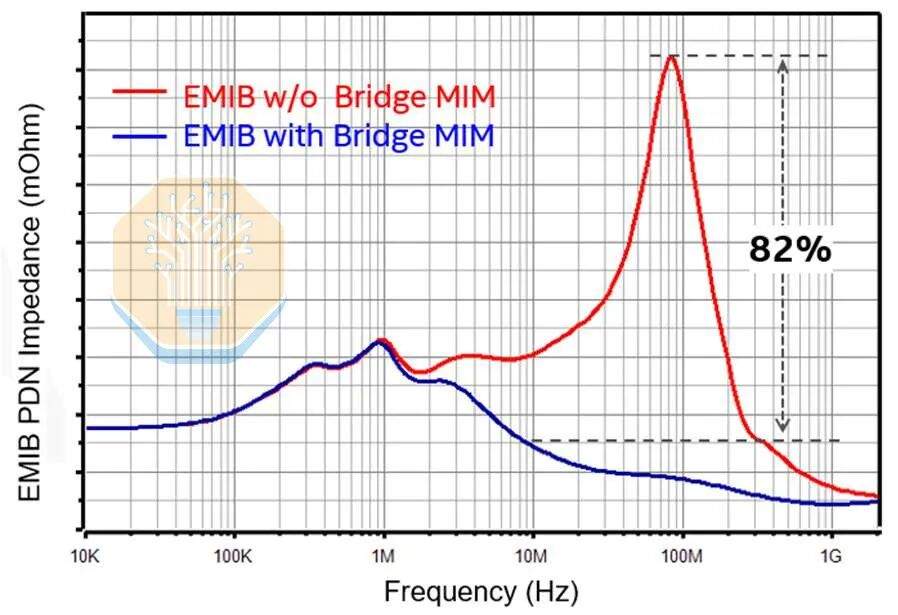
La transmisión de energía también se ha trasladado a la capa puente. EMIB-M introdujo condensadores metal-aislante-metal (MIM) entre M1 y M2, y EMIB-T mejora esto. Intel anunció una densidad de capacitancia de 500 nF/mm², aproximadamente equivalente al condensador MIM de Intel 18A. Intel afirma que, en comparación con un empaquetado EMIB-T sin condensadores MIM puente, estos condensadores puente pueden reducir la impedancia de corriente alterna de la red de distribución de energía (PDN) en más de un 82%.
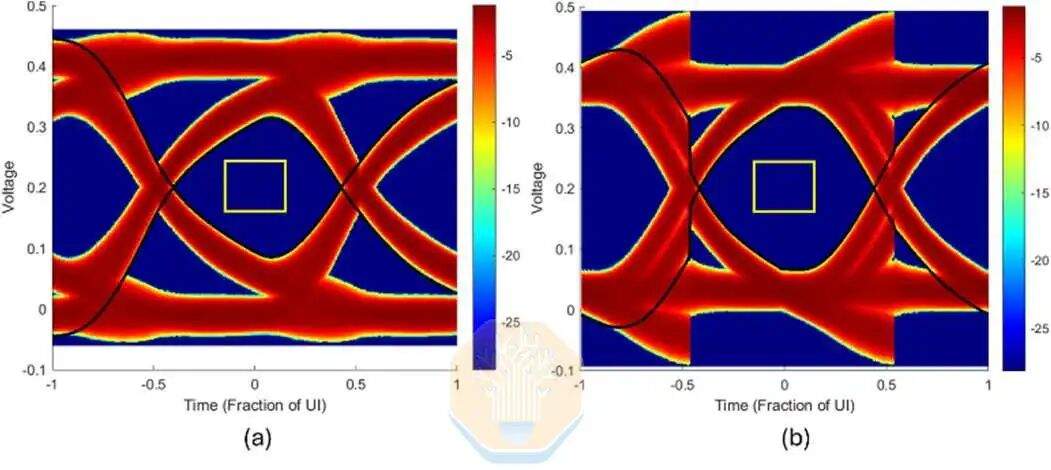
Intel también realizó simulaciones de EMIB-T con HBM4E. A una velocidad de 12 Gb/s, sin ecualización en recepción, el ancho del ojo de la interfaz de usuario de Intel era de aproximadamente el 67%. Con un ecualizador de retroalimentación de decisión (DFE) de un solo tap, este valor puede aumentar a aproximadamente el 72.5%. El DFE es un circuito del lado receptor que reduce la interferencia de bits anteriores después de que la señal pasa a través del canal del empaquetado.
Intel también simuló velocidades de transmisión más altas: 12.8 Gb/s, 14 Gb/s y 16 Gb/s. En todas las velocidades probadas, el ancho de la ventana de la interfaz de usuario se mantuvo por encima del 60%, con una ligera disminución en la capacitancia del pad.
La hoja de ruta de EMIB de Intel va más allá de la tecnología de puente pasivo que solo incluye cableado y condensadores. Las versiones futuras incluirán condensadores MIM puente de mayor densidad, chips puente de alta relación de aspecto de mayor tamaño, pasos de micro-bump inferiores a 25 micrómetros, puentes activos y reguladores de voltaje integrados dentro del chip EMIB. Intel también ha revelado el concepto de condensadores de zanja profunda (DTC) integrados en el núcleo del sustrato y condensadores eMIM-T de >2500 nF/mm² incrustados debajo del sustrato, aunque estas tecnologías aún no se han visto en productos EMIB enviados.
EMIB-T todavía está rezagado respecto a la plataforma CoWoS de TSMC en varios aspectos. TSMC ya ha logrado la integración de DTC/eDTC y ha avanzado más en reguladores de voltaje integrados e interconexiones locales de silicio activo (LSI). EMIB-T reduce la brecha, pero Intel todavía está alcanzando a un ecosistema que ha estado funcionando a gran escala durante años.
Marvell HBM personalizado
En el Día del Analista de la Industria de Marvell en 2024, Marvell anunció HBM personalizado. En ese momento, era una declaración vaga sin detalles técnicos. El diseño de HBM siempre ha girado en torno a la compatibilidad con JEDEC: pilas de DRAM estándar proporcionadas por proveedores de memoria, PHY HBM estándar en el acelerador y una interfaz ancha fija entre ellos. En la conferencia Hot Chips 2025, Marvell mostró el diseño del chip base personalizado.

En ECTC, Marvell finalmente proporcionó detalles a nivel de empaquetado del HBM4E personalizado.
La especificación JEDEC fija la interfaz entre la pila HBM y el host. Esto favorece la interoperabilidad: cualquier HBM de cualquier fabricante de memoria puede emparejarse con cualquier host compatible. Sin embargo, esto perjudica el consumo de energía, el rendimiento y el área. El ASIC host debe implementar una PHY HBM estándar y utilizar una disposición de pads y reglas de enrutamiento estandarizadas para cablear una interfaz paralela muy ancha. A medida que aumentan el tamaño del empaquetado y la velocidad de HBM, este límite fijo dificulta la optimización de la línea de costa, la densidad de cableado, la alimentación y la integridad de la señal.

La tecnología HBM personalizada no requiere ningún cambio en los chips de núcleo DRAM. En su lugar, se fabrica un chip base personalizado con una interfaz optimizada entre chips utilizando un proceso lógico avanzado. Este chip base personalizado puede integrar el controlador HBM, funciones de gestión y monitoreo, lógica personalizada e interfaces extendidas.

Marvell afirma que esto reduce la ocupación del ASIC host para la PHY HBM y la lógica asociada en aproximadamente un 60%, liberando directamente más espacio para cómputo, caché o E/S. Esta interfaz personalizada traslada la mayor parte de la interfaz del lado de la memoria al chip base HBM.
El ejemplo de Marvell utiliza 1024 canales a una velocidad de 32 Gb/s, alcanzando 4.1 TB/s, equivalente a una interfaz JEDEC HBM4(E) de 2048 bits a 16 Gb/s.
El cableado del empaquetado también se vuelve más fácil; la interfaz personalizada reduce la longitud del canal del interpositor de 6.5 mm a 1.5 mm, lo que permite a Marvell aumentar el ancho de banda manteniendo las mismas 9 capas de cableado y una línea/espacio (L/S) de 2/2 micrómetros.
En el ejemplo de Marvell, se utiliza un interpositor de capa de redistribución orgánica (RDL) en lugar de silicio, lo que reduce el costo del empaquetado. La línea/espacio del RDL orgánico es mucho menor que la del interpositor de silicio en CoWoS-S o los puentes de silicio en CoWoS-L y EMIB-T, lo que aumenta la dificultad del diseño. Marvell se basa en patrones de blindaje y cableado personalizados en diferentes partes para maximizar la densidad de ancho de banda mientras controla la diafonía.

En la conferencia GTC, Nvidia anunció que Feynman utilizará HBM personalizado. Las razones de Nvidia probablemente sean similares a las de Marvell: mayor ancho de banda, menor consumo de energía y menos área de chip del acelerador dedicada a HBM. Aproximadamente el 16% del área del chip de la GPU Rubin se utiliza para lógica y PHY relacionadas con HBM. El HBM personalizado permitiría a Nvidia trasladar la mayor parte de esta carga al chip base HBM.
El HBM personalizado también admite interfaces extendidas más allá del enlace HBM estándar. El chip base puede actuar como un controlador de memoria auxiliar y distribuir el tráfico a memoria adicional, en lugar de forzar que todo el tráfico de memoria pase a través de los canales limitados del borde del chip acelerador. Esta memoria adicional puede ser LPDDR de mayor capacidad y menor ancho de banda, o incluso una segunda capa de HBM. Esto permite que el acelerador expanda la capacidad de memoria sin ocupar los valiosos canales del borde del chip necesarios para E/S externas. Esto es particularmente importante para las próximas GPU MI450 y futuras MI500 de AMD, que admitirán LPDDR para aumentar la capacidad de memoria.
Interpositor HBM de Samsung
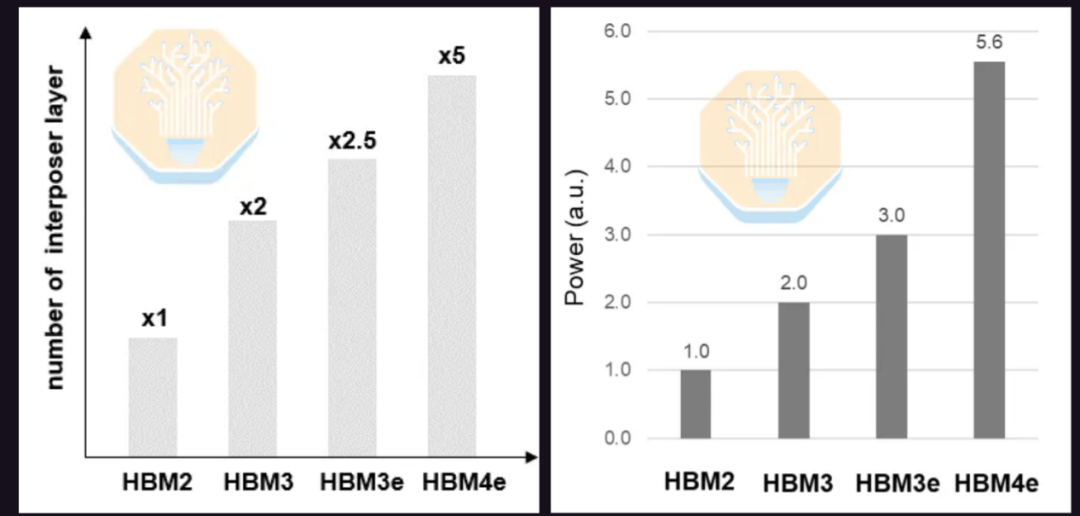
Samsung también presentó su solución HBM4E basada en interpositor. HBM4E aumenta la velocidad de transferencia de datos a 12 Gb/s y más, y duplica el número de pines de E/S, lo que aumenta la complejidad del cableado. Se estima que el número de capas de interpositor necesarias para HBM4E podría ser el doble que para HBM3E y cinco veces más que para HBM2. Debido al aumento en el número de pines de E/S y la mayor velocidad de transferencia de datos, se espera que el consumo de energía también aumente un 86% en comparación con HBM3E y 5.6 veces en comparación con HBM2.
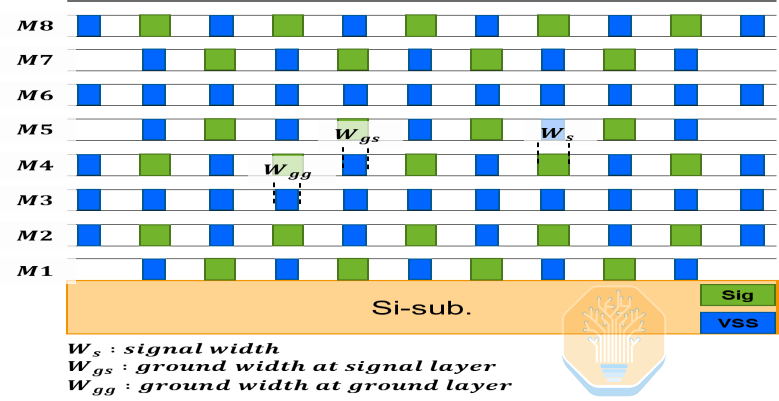
Samsung propuso una solución de interpositor de silicio de 8 capas, que, según afirman, reduce el número de capas en un 20% en comparación con los requisitos estimados. Este interpositor utiliza una disposición repetida de doble señal/tierra única entrelazada para blindar las señales de alta velocidad, con el 75% de las capas dedicadas al cableado de señales.
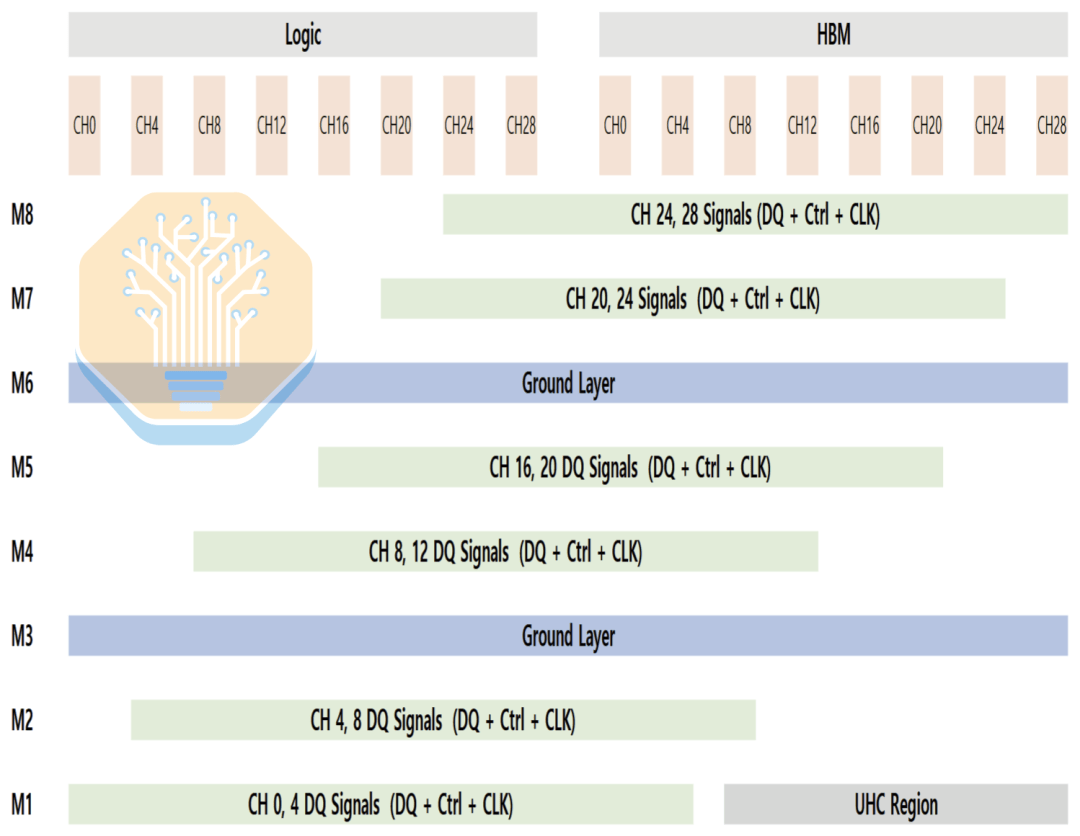
Otra característica clave del interpositor es el condensador de ultra alta densidad (UHC). Samsung no especifica la estructura exacta del condensador, pero es probable que sean similares a los condensadores MIM de Intel EMIB-T o los condensadores DTC de TSMC CoWoS. El condensador UHC solo puede colocarse en la capa M1, que también se utiliza principalmente para el cableado de señales, por lo que el área disponible es limitada.
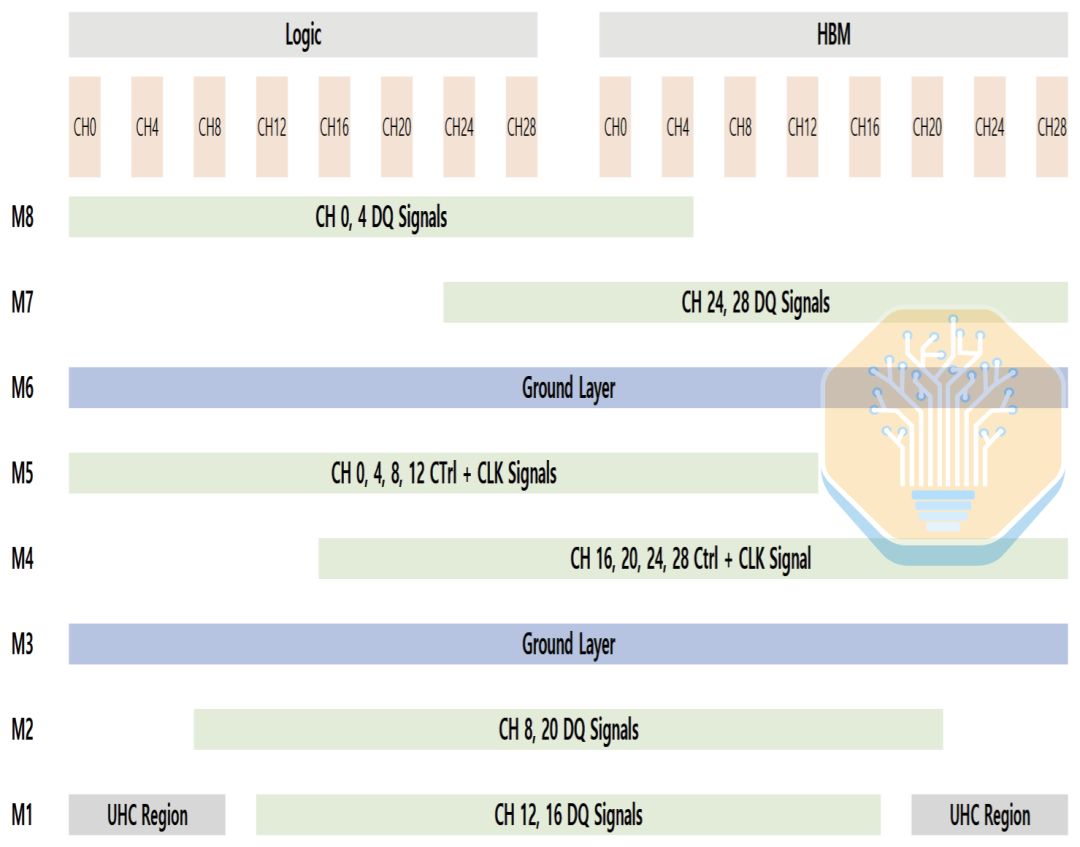
Si el cableado no está equilibrado, la capacitancia se desplaza hacia un lado de la interfaz, lo que provoca un rendimiento desigual de la red de distribución de energía (PDN) entre el lado lógico y el lado HBM. El diseño de Samsung redistribuye el cableado entre la capa M1 y otras capas, lo que permite que el condensador de ultra alta capacitancia (UHC) se distribuya de manera más uniforme en toda la interfaz. Esto reduce la impedancia de la PDN y el ruido de voltaje mientras se mantiene una densidad de cableado manejable.
Térmica de unión híbrida HBM de Samsung
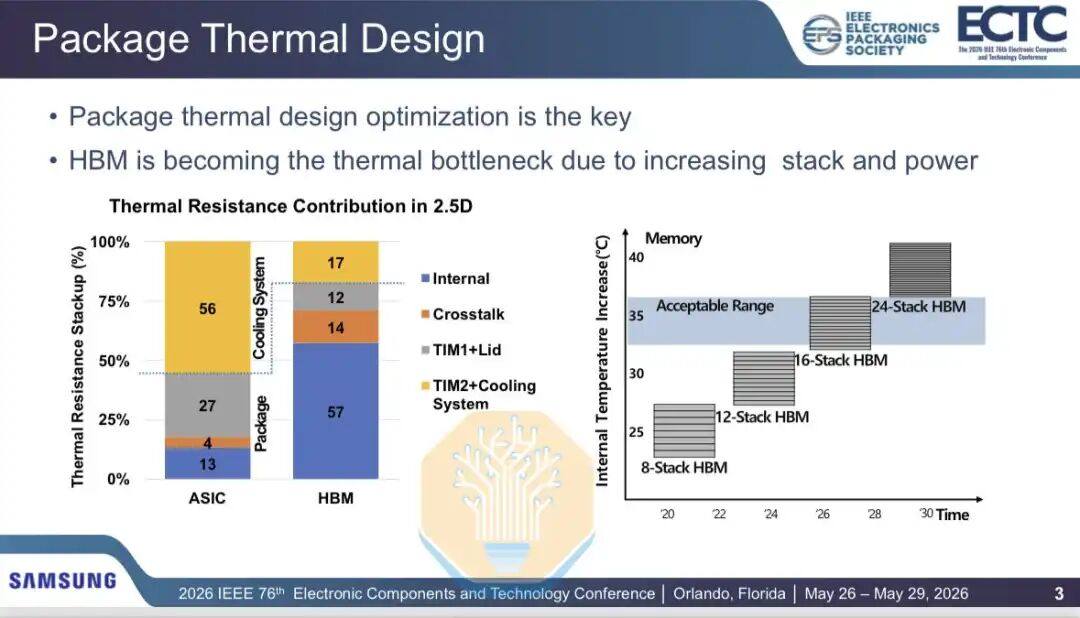
Samsung también discutió los problemas térmicos de HBM, particularmente la tecnología de unión híbrida. Las pilas HBM tienen cada vez más capas y son más rápidas, mientras que el consumo de energía del chip lógico subyacente también aumenta. Para HBM de 16 capas, la resistencia térmica es aceptable, pero a medida que las futuras generaciones de productos se muevan hacia HBM de 20 y 24 capas, se necesitarán nuevas soluciones.
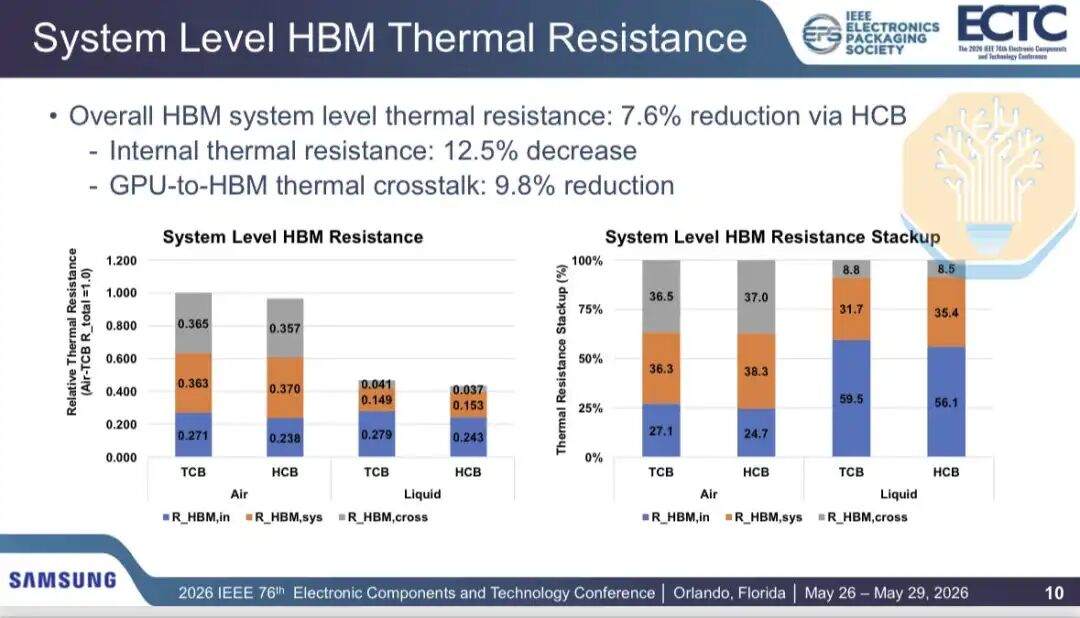
Samsung comparó el rendimiento de disipación de calor de HBM entre la unión por termocompresión (TCB) y la unión híbrida de cobre (HCB) en un empaquetado de GPU 2.5D que contiene 2 chips GPU y 8 pilas HBM, similar a la arquitectura Nvidia Blackwell. Los resultados muestran que la refrigeración por aire puede reducir la resistencia térmica interna de HBM en un 12.2%, y la refrigeración líquida en un 12.9%. La resistencia térmica total de HBM se reduce en un 3.5% con refrigeración por aire y en un 7.7% con refrigeración líquida.
Dado que HCB solo se dirige a una parte de la red de disipación de calor, las mejoras no son uniformes. Samsung divide la ruta térmica en resistencia térmica interna, resistencia térmica a nivel de sistema y diafonía de GPU a HBM. La resistencia térmica interna y la diafonía se reducen aproximadamente un 12.5% y un 9.8% respectivamente, pero la resistencia térmica a nivel de sistema, que incluye el material de interfaz térmica y el disipador, aumenta aproximadamente un 2.3%.
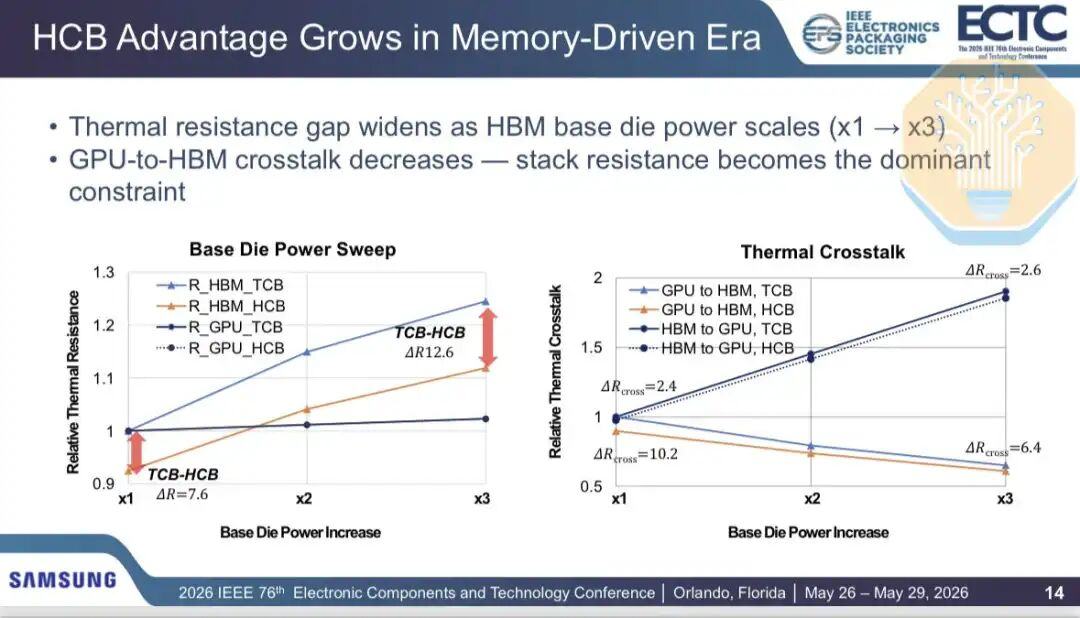
A medida que se transfiere más potencia al sustrato HBM (por ejemplo, en cargas de trabajo intensivas en memoria), el cuello de botella térmico se desplaza. Esto es particularmente importante para el HBM personalizado, donde el controlador de memoria y más lógica están integrados en el sustrato. La diafonía de GPU a HBM representa una proporción menor de la resistencia térmica total, disminuyendo del 13% cuando la potencia del sustrato se duplica al 5% cuando la potencia del sustrato se triplica.
Samsung afirma que la tecnología HCB puede permitir aumentar la temperatura del aire de entrada o aumentar la potencia del empaquetado. Según sus estimaciones, con HCB, la temperatura del aire de entrada puede aumentar de 1 a 2 °C manteniendo la potencia del empaquetado constante; o la potencia del empaquetado puede aumentar aproximadamente un 4% manteniendo la temperatura constante. Samsung también estima que la potencia de disipación de calor se reducirá aproximadamente un 7%.
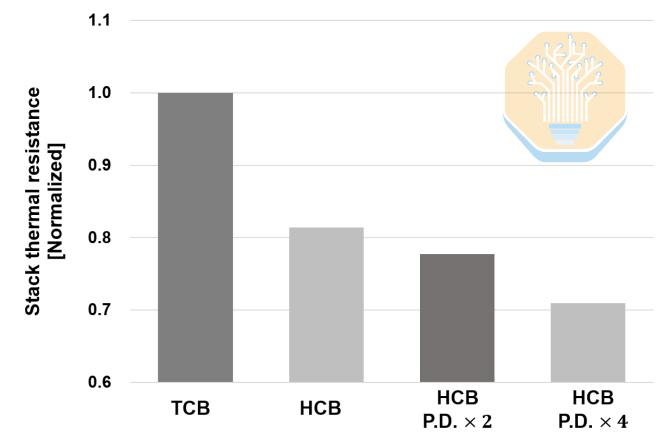
Samsung también estudió por separado el impacto de HCB a nivel de pila. Las mejoras aquí son mayores: en comparación con TCB, el HCB de referencia puede reducir la resistencia térmica de la pila en aproximadamente un 19%. Al aumentar el número de pads HCB, la reducción de la resistencia térmica puede alcanzar el 22.3% con una densidad de pads 2 veces mayor y el 29.1% con una densidad de pads 4 veces mayor.
Refrigeración por microfluidos
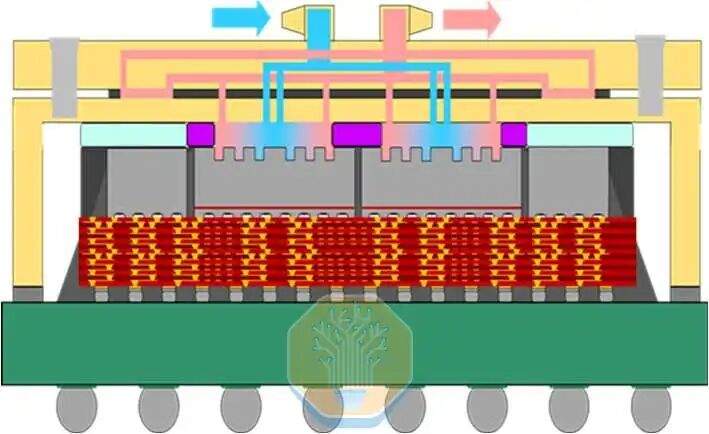
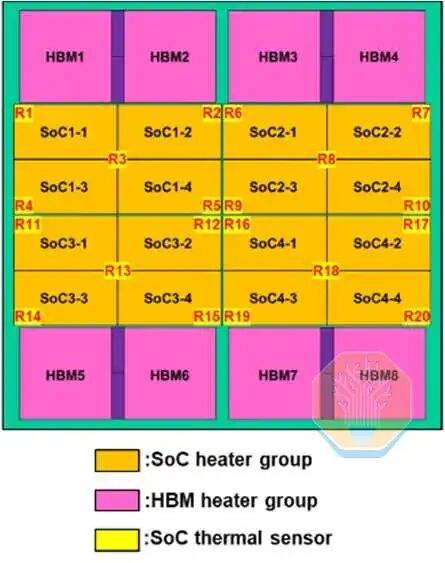
TSMC demostró tecnología de refrigeración directa de silicio en un chip CoWoS-R, utilizado en una plataforma de prueba grande similar a una GPU. CoWoS-R se diferencia de CoWoS-S en que utiliza materiales orgánicos en lugar de un interpositor de silicio. Se eligió CoWoS-R por su mejor tolerancia a la deformación y compatibilidad de proceso. La plataforma de prueba utiliza un interpositor de 3.3 veces la retícula, que contiene 4 chips SoC y 8 pilas HBM. Cada chip SoC consta de 4 grupos de calentadores SoC, que juntos cubren aproximadamente la mitad del área del interpositor.
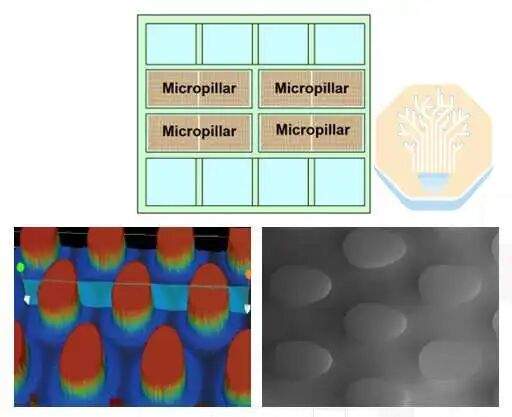
TSMC comparó tres soluciones: el empaquetado tradicional con tapa y placa fría, el empaquetado sin tapa con placa fría y su diseño de empaquetado directo de silicio con micropilares. Las soluciones con y sin tapa aún utilizan placas frías tradicionales y material de interfaz térmica (TIM). La última solución forma micropilares directamente en la parte posterior del chip SoC.
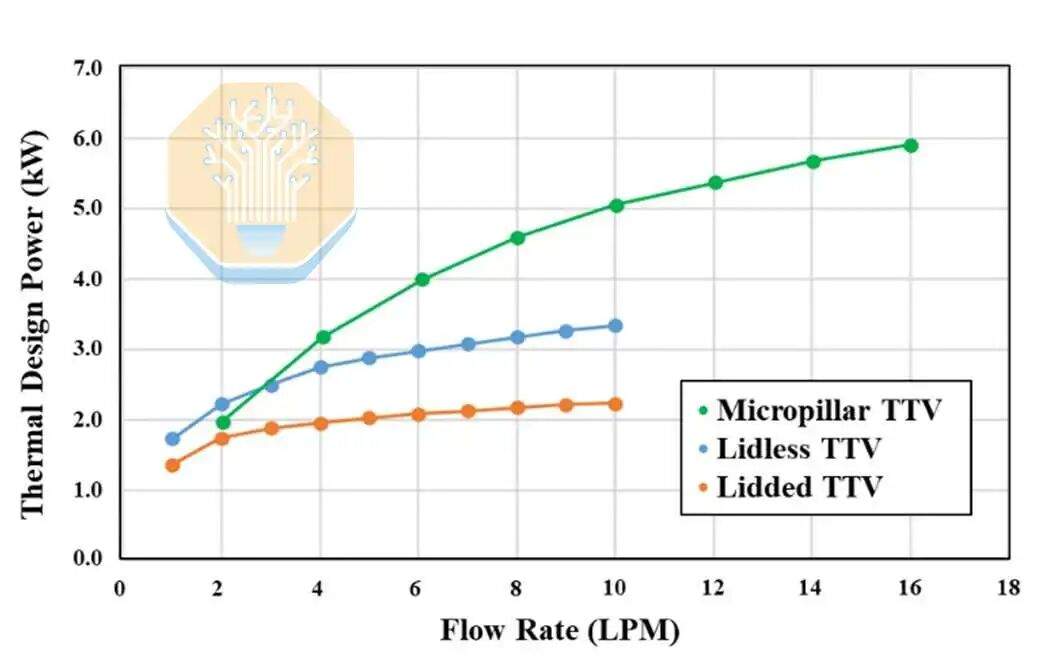
Con refrigeración convencional, a un caudal de 1-2 litros por minuto (LPM), la disipación de calor del empaquetado con tapa es de 1.9-2.3 kW, mientras que la del empaquetado sin tapa es de 2.5-3.0 kW, utilizando agua desionizada a 40 °C como refrigerante. Ambas soluciones se saturan después de un caudal superior a 4 LPM, ya que el material de interfaz térmica (TIM) se convierte en el cuello de botella.
El vehículo de prueba con micropilares mostró un rendimiento comparable al de la placa fría sin tapa a un caudal de 2 LPM, y luego superó a este a caudales más altos, alcanzando una potencia de disipación de 4 kW a 4 LPM y 5.3 kW a 8 LPM. TSMC informó que la potencia de disipación superó uniformemente los 5 kW en todo el vehículo de prueba. La estructura de micropilares acerca el refrigerante líquido a la fuente de calor, lo que facilita la mejora del rendimiento de disipación.
Sin embargo, la estructura de micropilares no es perfecta. TSMC debe formar los micropilares después de completar el proceso de chip en empaquetado (CoW), evitando dañar la estructura CoWoS-R y desarrollando nuevos materiales de sellado para garantizar que el refrigerante permanezca sellado a pesar de la deformación del empaquetado y la falta de coincidencia del coeficiente de expansión térmica. Las muestras de prueba pasaron la prueba de nivel de sensibilidad a la humedad 4 (MSL4) sin fugas de helio ni delaminación del sellador.
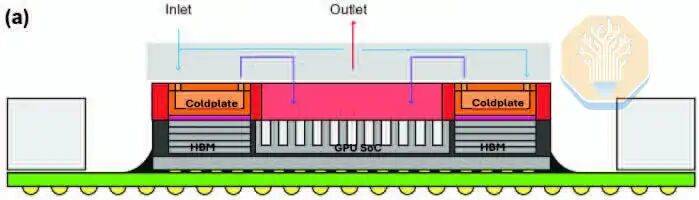
La solución de disipación de calor de Microsoft difiere de la de TSMC en la estructura de disipación. TSMC utiliza micropilares de silicio, mientras que Microsoft emplea microcanales rectos grabados en la oblea de silicio de la GPU. Microsoft no utilizó una plataforma de prueba térmica, sino que probó directamente en una GPU Nvidia GH200. Esto puede permitir a Microsoft capturar con mayor precisión la distribución térmica real y las zonas calientes. Microsoft probó múltiples cargas de trabajo en la GPU, como HPCG y HPL, cada una con diferentes características de presión computacional y de memoria.
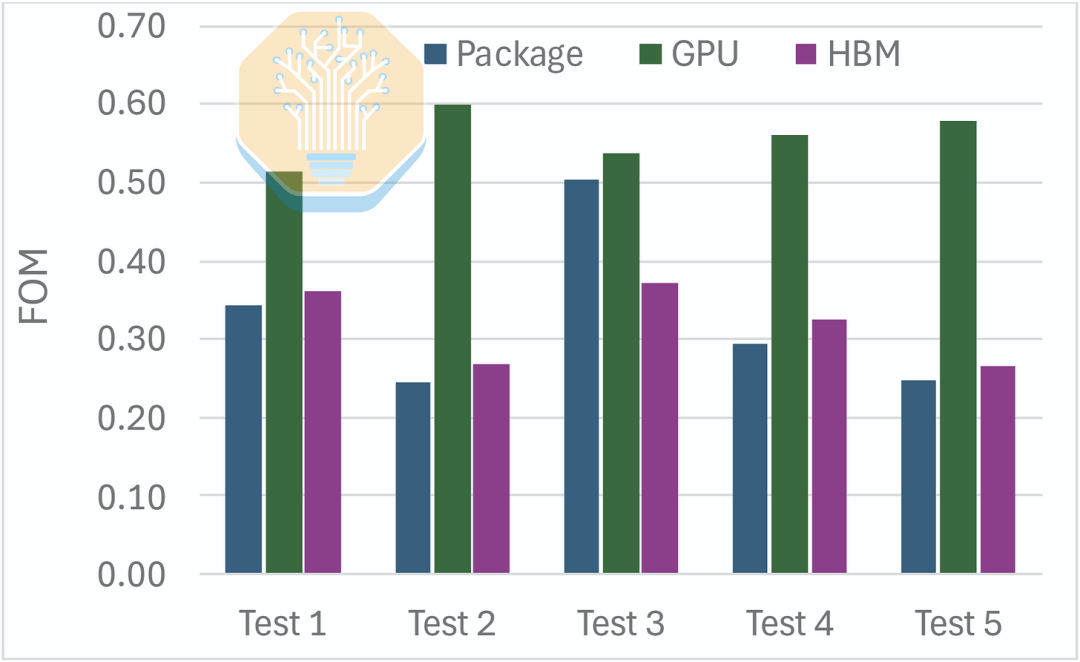
Bajo estas cargas de trabajo, Microsoft informó una reducción del 51-60% en la resistencia térmica de la unión a la entrada de la GPU a un caudal de 1 LPM. La mejora para HBM fue menor, del 27-37%, ya que todavía se enfría a través de la placa fría y el material térmico. En general, esto resultó en una reducción del 50% en la resistencia térmica del empaquetado.
Microsoft también presentó algunos datos preliminares de fiabilidad. Aunque el rendimiento térmico es importante, la implementación en centros de datos también requiere alta fiabilidad y bajo tiempo de inactividad. Durante un período de 6 meses, Microsoft registró solo 9 posibles eventos de obstrucción en aproximadamente 4370 observaciones. La tasa de obstrucción disminuyó con el tiempo, lo que indica inestabilidad durante la instalación inicial seguida de una operación más estable. Incluso después de 6 meses, no se midió corrosión de silicio en los microcanales. A nivel de nodo, el GH200 completó con éxito pruebas de referencia repetidas durante 3 semanas, seguidas de una operación continua durante 1 semana a una potencia de empaquetado estable. Microsoft todavía está probando el tiempo medio entre fallos (MTBF) y la disponibilidad a nivel de clúster.