es.wedoany.com Noticia: Google ha presentado TurboQuant, una tecnología de compresión de memoria para IA que busca optimizar el uso de memoria en modelos de lenguaje grandes y motores de búsqueda vectorial. Esta tecnología puede reducir la huella de memoria aproximadamente 6 veces, mientras aumenta la velocidad de cálculo de la atención hasta 8 veces, sin pérdida de precisión del modelo. Se espera que TurboQuant se presente oficialmente a finales de este mes en la conferencia ICLR 2026 que se celebrará en Río de Janeiro, Brasil.
TurboQuant combina dos técnicas complementarias: PolarQuant y el algoritmo QJL. PolarQuant simplifica la estructura geométrica de los vectores de datos mediante rotaciones aleatorias para lograr una compresión de alta calidad; QJL aprovecha una capacidad de compresión residual de aproximadamente 1 bit para eliminar sesgos, garantizando la precisión de las puntuaciones de atención. Google declaró en su blog: "En esencia, el algoritmo crea una taquigrafía de alta velocidad sin sobrecarga de memoria."
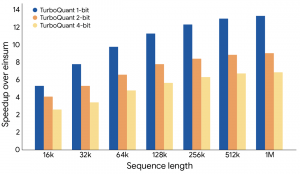
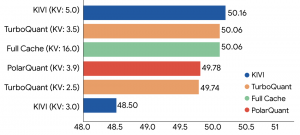
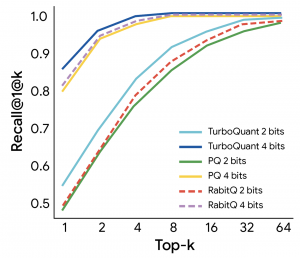
En múltiples pruebas comparativas, como ZeroSCROLLS y Needle in a Haystack, TurboQuant redujo significativamente el uso de memoria manteniendo una alta precisión. Las pruebas mostraron que puede comprimir la precisión de la caché de 16 bits a aproximadamente 3 bits, logrando una aceleración 8 veces mayor en GPU H100 y mejorando la tasa de recuperación en búsquedas vectoriales.
TurboQuant no solo optimiza la eficiencia de compresión, sino que también alivia las limitaciones del ancho de banda de memoria, abriendo nuevos caminos para la escalabilidad de los sistemas de IA. A medida que los modelos crecen en tamaño, esta tecnología que reduce los requisitos de memoria sin afectar la precisión podría convertirse en un factor clave para impulsar el desarrollo de la IA.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com