es.wedoany.com Noticia: El 1 de junio, la empresa china de inteligencia artificial MiniMax lanzó su nuevo modelo general MiniMax M3. Este modelo se basa en la arquitectura MiniMax Sparse Attention desarrollada internamente, con una API que admite una ventana de contexto de hasta 1 millón de tokens, garantizando al menos 512.000 tokens utilizables. Está enfocado principalmente en agentes de largo alcance, tareas complejas de código y aplicaciones multimodales nativas.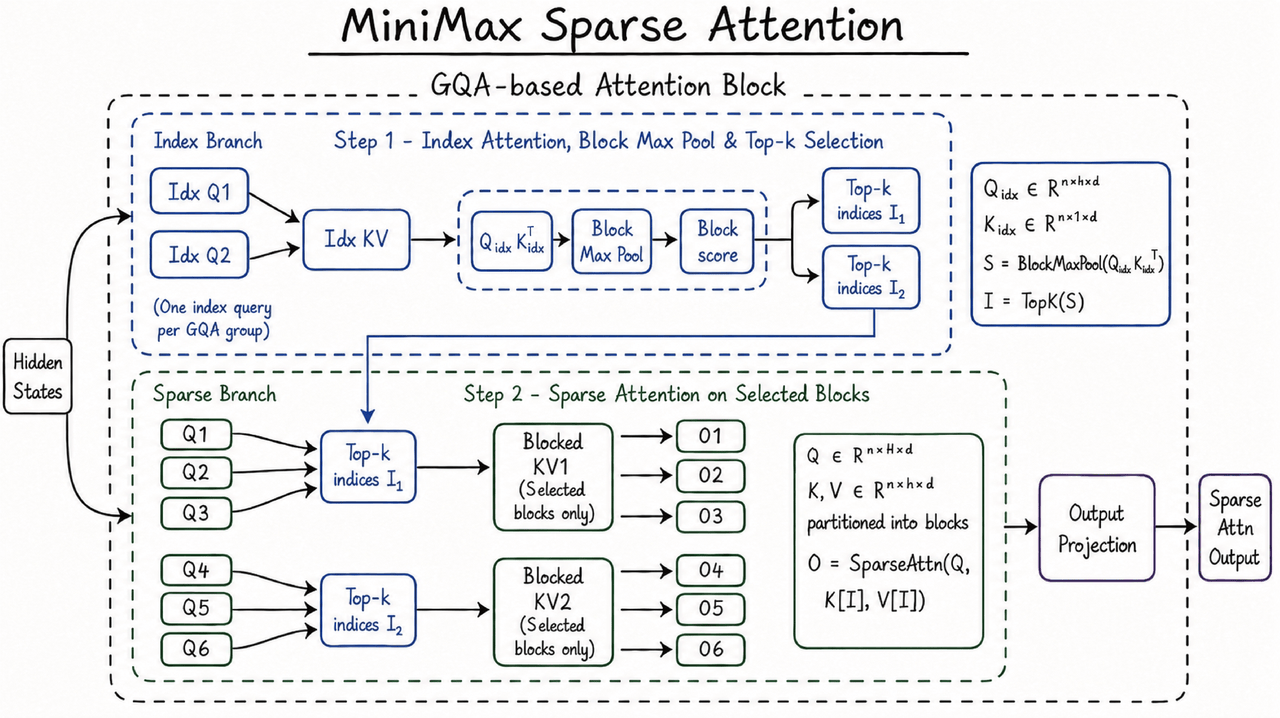
El cambio central de MiniMax M3 radica en que la capacidad de contexto largo pasa de ser un "indicador de parámetros" a una "carga de trabajo de ingeniería". En la etapa en que las aplicaciones de modelos grandes entran en la fase de agentes, los modelos ya no solo necesitan manejar preguntas y respuestas individuales o generación de texto corto, sino tareas de larga duración que entrelazan repositorios de código, documentación de productos, registros de tareas, registros de llamadas a herramientas, imágenes y videos. Una ventana de contexto de 1 millón de tokens significa que MiniMax M3 puede retener más información ascendente y descendente en una sola cadena de tareas, reduciendo la pérdida de información causada por truncamientos frecuentes, resúmenes repetidos y recuperación externa. Para escenarios como desarrollo de software, reproducción de investigaciones científicas, consultas en bases de conocimiento empresarial, comprensión de videos largos y automatización de oficinas complejas, el contexto largo se está convirtiendo en una capacidad fundamental para que los modelos puedan integrarse de manera estable en los procesos de producción.
Esta capacidad está respaldada por la arquitectura MiniMax Sparse Attention desarrollada internamente por MiniMax. El mecanismo de atención completa tradicional enfrenta un rápido aumento en la carga computacional a medida que se expande la longitud del contexto. MSA mejora la eficiencia computacional en contextos largos mediante la atención dispersa, permitiendo que MiniMax M3 mantenga un rendimiento de inferencia utilizable en ventanas de contexto de un millón de tokens. Según información oficial, bajo una longitud de contexto de 1 millón, la carga computacional por token de M3 es aproximadamente 1/20 de la del modelo anterior, la velocidad en la fase de prellenado aumenta más de 9 veces y la velocidad en la fase de decodificación aumenta más de 15 veces. Para desarrolladores y usuarios empresariales, estas mejoras de eficiencia afectan directamente el costo de la API, la velocidad de respuesta y la capacidad de ejecución continua de tareas largas, y también determinan si MiniMax M3 puede pasar de escenarios de demostración a llamadas comerciales de mayor frecuencia.
MiniMax M3 también enfatiza las capacidades de codificación y de agente. Las tareas de ingeniería de software se han convertido en un escenario clave en la competencia de capacidades de los modelos grandes, ya que el flujo de trabajo real de desarrollo generalmente incluye aclaración de requisitos, modificación de código, retroalimentación de pruebas, llamadas a herramientas, iteraciones de versiones y colaboración en múltiples rondas. MiniMax reveló que M3 ha obtenido altos puntajes en evaluaciones como SWE-Bench Pro, Terminal-Bench 2.1, KernelBench Hard y MCP Atlas, y ha entrenado al modelo para adaptarse a escenarios de colaboración continua a través de un marco de simulación de usuarios. Esta dirección muestra que MiniMax M3 no solo mejora la capacidad de "escribir un fragmento de código", sino que intenta cubrir toda la cadena de desarrollo, desde la descomposición de tareas, la ejecución, la verificación hasta la corrección repetida.
La multimodalidad también es una de las capacidades clave de MiniMax M3. El modelo introduce datos multimodales mixtos desde las primeras etapas del entrenamiento, lo que permite que texto, imágenes y videos se procesen de manera coordinada en una sola tarea. En casos oficiales, MiniMax M3 se utiliza para tareas de larga duración como la reproducción de experimentos de artículos, la optimización de operadores CUDA y la automatización del flujo de entrenamiento de modelos, lo que demuestra el valor combinado del contexto largo, la capacidad de codificación, las llamadas a herramientas y la comprensión multimodal. Para las aplicaciones empresariales de IA, esta capacidad combinada significa que el modelo puede leer documentos, comprender gráficos, analizar registros, generar código y llamar a herramientas al mismo tiempo, expandiendo el límite de las aplicaciones de agentes de "capacidades puntuales" a "ejecución entre pasos".
El lanzamiento de MiniMax M3 también refleja que la competencia de modelos grandes en China está pasando de simples parámetros de modelo, precios y experiencia de diálogo general, a capacidades más cercanas al entorno de producción, como contexto largo, ejecución de agentes, ingeniería de código y fusión multimodal. A medida que las empresas integran modelos grandes en procesos de I+D, operaciones, servicio al cliente, oficina y gestión del conocimiento, los fabricantes de modelos deben resolver simultáneamente problemas de rendimiento, costo, capacidad de contexto, estabilidad y ecosistema de herramientas. La inversión de MiniMax M3 en contexto de un millón de tokens y la arquitectura MSA indica que los agentes de tareas largas se están convirtiendo en un nuevo punto focal de competencia para la comercialización de modelos grandes.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com