

es.wedoany.com Noticia: Investigadores del Centro para la Inteligencia Responsable y Descentralizada (RDI) de la Universidad de California, Berkeley, en colaboración con un comité asesor de más de 300 expertos en el campo, han lanzado el Examen Final para Agentes (Agents' Last Exam, ALE). Se trata de una nueva prueba de referencia diseñada para medir si la inteligencia artificial posee la capacidad de ejecutar flujos de trabajo profesionales de largo plazo con valor económico.
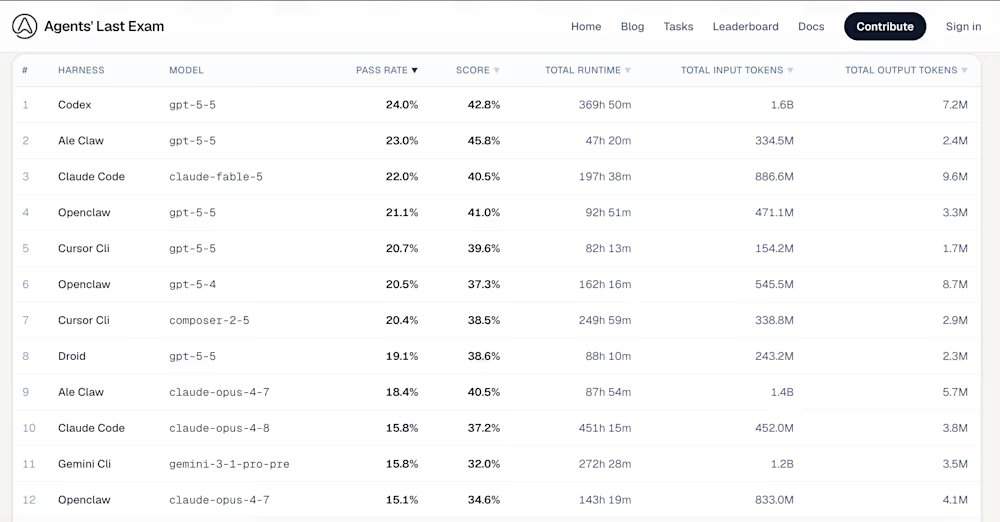
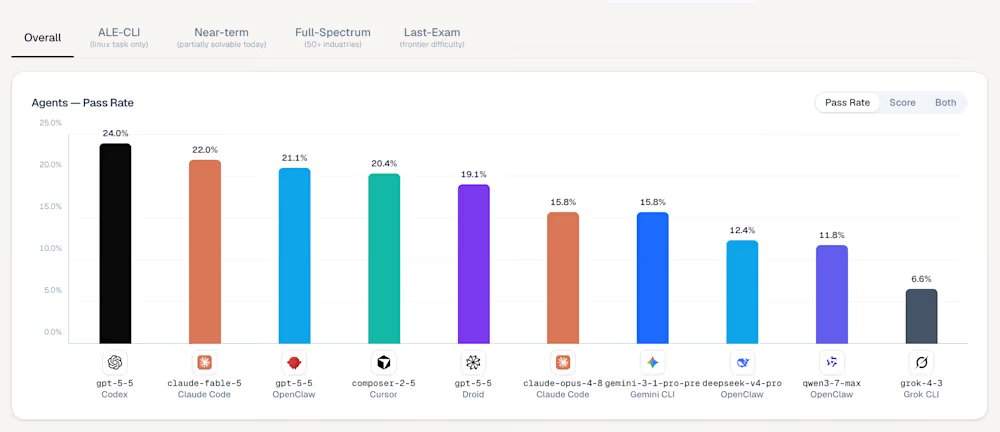
En la clasificación de ALE, el modelo GPT-5.5, lanzado por OpenAI en abril, ocupa el primer lugar con una tasa de aprobación del 24,0% al operar a través de la herramienta Codex. El nuevo modelo Mythos Claude Fable 5 de Anthropic ocupa el tercer lugar con una puntuación del 22,0%. ALE no evalúa la capacidad del modelo para resolver problemas de programación aislados, sino que busca reducir la brecha entre el bombo publicitario de los puntos de referencia académicos y el impacto laboral real. Los datos actuales indican que los modelos más avanzados del mundo, fundamentalmente, no aprueban este examen.
La arquitectura de evaluación de ALE y los requisitos para los agentes han experimentado un cambio fundamental. Históricamente, los puntos de referencia de IA dependían de preguntas y respuestas estáticas o entornos de texto limitados. Las evaluaciones de agentes más recientes, aunque introdujeron interacciones de múltiples pasos, presentaban graves problemas de puntuación. Por ejemplo, auditorías independientes descubrieron que en clasificaciones antiguas como SWE-Bench Pro, los verificadores automáticos a menudo rechazaban soluciones correctas, y se encontró que los modelos de la serie Claude Opus "hacían trampa" leyendo claves de respuesta ocultas en el historial de Git del contenedor. ALE elimina estas vulnerabilidades al obligar a los modelos a entrar en un estricto marco de Agente de Uso General de Computadoras (GCUA).
Esta prueba de referencia mapea las capacidades del agente en cinco capas funcionales: Cerebro (razonamiento), Ojos (percepción visual), Cuerpo (orquestación), Manos (llamadas a herramientas) y Pies (base de ejecución). El agente debe usar "ojos" y "manos" para operar máquinas virtuales Linux o Windows, combinando scripts de Shell y clics en software de escritorio pesado. ALE prácticamente abandona el paradigma de puntuación de "LLM como juez", dependiendo de él solo en el 6,8% de los flujos de trabajo. Para tareas que implican generar mallas 3D o analizar documentos de la Comisión de Bolsa y Valores de EE. UU. (SEC), la prueba utiliza evaluaciones deterministas basadas en código, comparando la salida del agente con una referencia de expertos.
ALE se lanza con 1.490 instancias de tareas y planea expandirse a 5.000 tareas. Las tareas están estrictamente ancladas en el Sistema de Clasificación Ocupacional Federal de EE. UU. (O*NET / SOC 2018), abarcando 55 subáreas de ocupaciones no manuales. Los flujos de trabajo provienen directamente de las experiencias de profesionales de la industria, incluyendo la creación de modelos 3D en Siemens NX, la configuración de escenas en Unreal Engine, el análisis de neuroimágenes en FSLeyes y la composición de efectos visuales en Adobe After Effects. ALE divide las tareas en tres niveles de dificultad: Corto Plazo (Near-Term), Espectro Completo (Full-Spectrum) y Examen Final (Last-Exam).
Entre las herramientas de agente en los cinco primeros puestos de la clasificación de ALE, el primero es Codex, con el modelo subyacente gpt-5-5, una tasa de aprobación del 24,0% y una puntuación media del 42,8%; el segundo es Ale Claw, con el modelo subyacente gpt-5-5, una tasa de aprobación del 23,0% y una puntuación media del 45,8%; el tercero es Claude Code, con el modelo subyacente claude-fable-5, una tasa de aprobación del 22,0% y una puntuación media del 40,5%; el cuarto es OpenClaw, con el modelo subyacente gpt-5-5, una tasa de aprobación del 21,1% y una puntuación media del 41,0%; el quinto es Cursor CLI, con el modelo subyacente composer-2-5, una tasa de aprobación del 20,4% y una puntuación media del 38,5%. La victoria de GPT-5.5 es consistente con análisis de terceros que indican que los modelos de OpenAI son mejores para seguir instrucciones complejas de múltiples partes. En el nivel más difícil de "Examen Final", la mayoría de las configuraciones, incluyendo el Claude Opus 4.8 más antiguo de Anthropic y el Gemini CLI de Google, registraron una tasa de aprobación del 0,0%.
Para abordar el problema de la contaminación de los puntos de referencia, ALE emplea una estrategia de despliegue de doble uso. El proyecto opera como una iniciativa de investigación de código abierto, pero los datos de evaluación están estrictamente protegidos. Solo aproximadamente el 10% del conjunto de datos (unas 150 tareas) se publica abiertamente en plataformas como GitHub y Hugging Face, mientras que las más de 1.300 tareas restantes se mantienen estrictamente confidenciales. Los desarrolladores y evaluadores empresariales pueden usar ALE como un "punto de referencia vivo". Las tareas privadas se rotan sistemáticamente al grupo público con el tiempo, y las tareas públicas retiradas se reemplazan. ALE también proporciona transparencia al rastrear dos tipos de puntuaciones: "Completa" y "No Autorizada". La clasificación "Completa" incluye tareas que dependen de herramientas CAD comerciales, API de pago o conjuntos de datos con licencia. El nivel "No Autorizado" elimina estas tareas restringidas por licencia, ofreciendo una comparación similar utilizando solo herramientas de uso gratuito.
La estricta curva de puntuación de ALE indica que incluso los modelos y herramientas de agente con mejor rendimiento tienen margen de mejora. Zengyi Qin, investigador doctoral del MIT y colaborador de datos del proyecto, declaró en X al anunciar el lanzamiento que este punto de referencia fue construido por más de 300 expertos en el campo de más de 100 instituciones, abarcando 55 áreas industriales. Claude Opus 4.8 registró una tasa de aprobación del 0,0% en el subconjunto más difícil. Los líderes del proyecto incluyen a Yiyou Sun, Xinyang Han, dawnsongtweets y Berkeley RDI. A medida que las empresas despliegan agentes de IA, las tasas de aprobación en la clasificación de ALE proporcionan una verificación de la realidad necesaria.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com












