es.wedoany.com Noticia: La Universidad Renmin de China, en colaboración con Microsoft Research, ha lanzado el marco Arbor, que transforma la optimización autónoma de sistemas de IA de un proceso de prueba y error a un mecanismo de aprendizaje acumulativo. Este marco, mediante la gestión estructurada de hipótesis, logra una mejora de rendimiento verificable superior a 2,5 veces en tareas de ingeniería reales.

A medida que los grandes modelos de lenguaje y los sistemas de IA aumentan sus capacidades, la optimización autónoma se convierte en un desafío central. Los equipos de ingeniería, al optimizar agentes de IA, a menudo necesitan ajustar simultáneamente múltiples parámetros como estrategias de fragmentación, métodos de recuperación y avisos del sistema. Estos ajustes están entrelazados, lo que dificulta una atribución precisa y provoca una baja eficiencia en el proceso de optimización. Jiajie Jin, coautor del artículo, señala que simplemente darle más tiempo o recursos computacionales al agente de codificación no produce mejores resultados: "Si el objetivo es vago o los indicadores son fáciles de manipular, ejecutar durante más tiempo generalmente solo genera más rápido 'mejoras' que nadie realmente quiere".
Los agentes de codificación existentes dependen de registros de conversación como memoria, pero las tareas de optimización autónoma implican cientos de rondas de interacción, lo que fácilmente supera los límites de la ventana de contexto. A los agentes les resulta difícil retener evidencia factual en un historial extenso, pierden la estructura general del proceso de investigación y tienden a estancarse en fracasos tempranos o a perseguir fluctuaciones ruidosas en la evaluación. Al mismo tiempo, los marcos generales organizan las cadenas de llamadas a herramientas en un árbol de trabajo compartido, lo que impide probar hipótesis paralelas en entornos aislados.
Arbor resuelve este desafío mediante una arquitectura de separación superior-inferior: el coordinador actúa como investigador principal, conoce el estado global del estudio de optimización, propone hipótesis y decide la dirección experimental, sin editar directamente el repositorio de código; el ejecutor es un agente de vida corta que prueba hipótesis específicas en un árbol de trabajo git independiente. Ambos componentes colaboran mediante un mecanismo de "refinamiento del árbol de hipótesis", representando el proceso de investigación como un árbol de ramas persistente, donde cada nodo vincula una hipótesis, artefactos ejecutables, evidencia factual y conocimientos destilados. El coordinador coloca ideas amplias en el nodo raíz y refinamientos específicos en los nodos hoja, pudiendo explorar múltiples direcciones competitivas simultáneamente. Los experimentos fallidos se registran como restricciones negativas, evitando que el sistema repita los mismos errores.
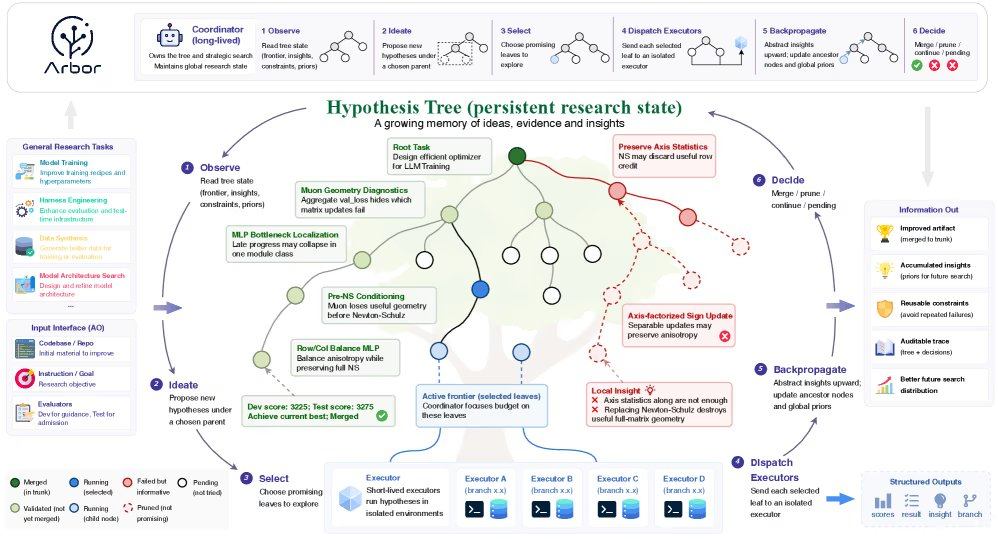
En escenarios reales de ingeniería, Arbor logra una atribución clara de propiedades al tratar cada palanca de optimización como una hipótesis separada. Tras recibir el informe del ejecutor, el coordinador escribe la evidencia en el árbol y propaga el conocimiento hacia el nodo padre. Para evitar el sobreajuste, el marco impone una "puerta de fusión", probando las candidatas en un árbol de trabajo independiente y fusionándolas con la rama principal actual solo si mejoran la puntuación de prueba de retención.
Los investigadores evaluaron Arbor en un conjunto de tareas de optimización autónoma basadas en entornos de investigación reales y en el punto de referencia de ingeniería de aprendizaje automático MLE-Bench Lite. El conjunto AO abarca tareas como entrenamiento de modelos, ingeniería de marcos y síntesis de datos. Al utilizar modelos base como Claude Opus 4.6, GPT-5.5 y Gemini-3-Flash, la ganancia relativa promedio de Arbor fue más de 2,5 veces superior a la de Codex y Claude Code. En la tarea BrowseComp de optimización de agentes de búsqueda, Arbor elevó la precisión de retención del sistema del 45,33 % al 67,67 %, mientras que Codex y Claude Code se quedaron en el 50 % y el 53,33 %, respectivamente. En MLE-Bench Lite, Arbor obtuvo los resultados más sólidos al estar equipado con GPT-5.5.
Arbor muestra resiliencia frente al sobreajuste. En el experimento Terminal-Bench 2.0, Claude Code obtuvo una puntuación de desarrollo de 75, pero descendió a 71 en los datos de retención; Arbor tuvo una puntuación de desarrollo más baja, 72,22, pero alcanzó la puntuación de retención más alta, 77,36. Los experimentos de transferencia entre tareas mostraron que el repositorio optimizado para la tarea BrowseComp podía mejorar significativamente el rendimiento en tareas no relacionadas como HLE y DeepSearchQA.
El marco está diseñado para construirse sobre flujos de trabajo Git existentes. Jin indica que Arbor genera ramas git ordinarias, que pueden ser revisadas directamente mediante los procesos existentes de revisión de código y revisión humana. El mayor costo de implementación proviene del consumo de tokens generado por el mantenimiento del coordinador y la gestión del árbol, así como de los recursos computacionales y de disco de los múltiples árboles de trabajo aislados. El marco es adecuado para tareas con indicadores confiables claros, que toleren horizontes temporales largos y que presenten múltiples direcciones de búsqueda razonables, como la optimización de tuberías, la calidad de la síntesis de datos y el ajuste del entrenamiento de modelos. No debe aplicarse a tareas de latencia en tiempo real, reparaciones simples o escenarios con indicadores de evaluación defectuosos. Jin considera que el próximo paso evolutivo es llevar los artefactos de cada nodo de una puntuación escalar única a una búsqueda multiobjetivo de Pareto que incluya vectores de precisión, latencia y costo.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com