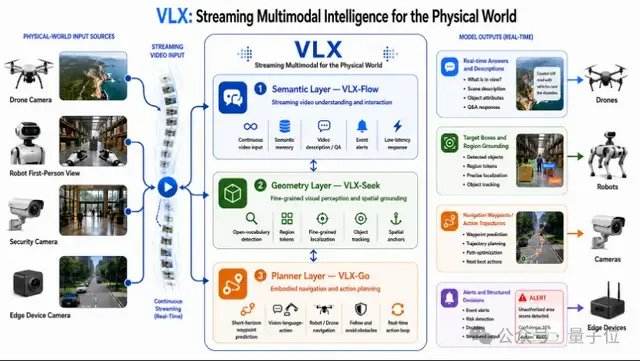
es.wedoany.com Noticia: La empresa de inteligencia artificial de Hangzhou, Om AI, ha lanzado la serie VLX, el primer modelo multimodal de flujo continuo para el mundo físico en dispositivos de borde a nivel mundial. Esta serie incluye tres modelos que se lanzarán en tres días: VLX-Flow se encarga de la percepción continua en tiempo real, permitiendo que el video fluya como agua, mientras el modelo observa, piensa y actualiza el estado del mundo en tiempo real; VLX-Seek se encarga de la localización precisa, pasando de ver a observar con claridad para localizar rápidamente el objetivo; VLX-Go se encarga de la toma de decisiones de acción, transformando los resultados de la percepción y localización en acciones reales, definiendo la dirección del movimiento y los pasos a seguir.
Estos tres modelos conectados forman un ciclo completo de capacidades del modelo multimodal, desde la percepción continua, la localización precisa hasta la toma de decisiones de acción. Su diseño nativo para dispositivos de borde permite que el modelo funcione realmente en dispositivos como teléfonos móviles, drones y robots.
No es la primera vez que Om AI incursiona en el campo del lenguaje visual. El año pasado, la empresa lanzó VLM-R1, el primer proyecto de código abierto a nivel mundial que introduce el paradigma de aprendizaje por refuerzo DeepSeek R1 en modelos de lenguaje visual. En 12 horas, obtuvo más de 2000 estrellas en GitHub, alcanzó el primer lugar en la lista de tendencias globales de GitHub en 48 horas y hasta ahora ha acumulado más de 6000 estrellas.
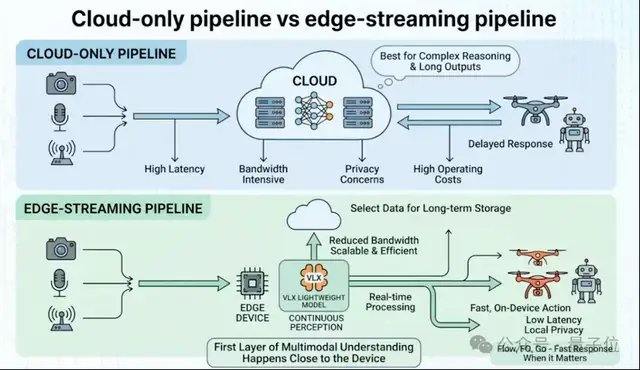
La serie VLX se diseñó en torno a dos palabras clave: dispositivos de borde y multimodal de flujo continuo. El llamado multimodal de flujo continuo se refiere a la capacidad de la IA para percibir el entorno de manera continua y en tiempo real en el mundo físico, formando una cadena completa de capacidades desde la percepción hasta la localización precisa y la acción. Esto difiere del multimodal de flujo continuo en los asistentes de voz, que enfatiza la interacción en tiempo real entre humanos y la IA, mientras que VLX se centra en que la IA observe, juzgue y accione continuamente en el mundo físico, logrando el salto de ver imágenes a realizar tareas. Con el rápido desarrollo de campos como la inteligencia incorporada, la inteligencia espacial y la generación de video, los modelos de lenguaje visual ya no son solo un módulo de capacidad de los modelos de lenguaje, sino que se están convirtiendo gradualmente en una nueva generación de infraestructura para la comprensión espacial, la comprensión de video e incluso la planificación de acciones. Los datos de CVPR de este año muestran que la proporción de artículos sobre modelos de lenguaje visual y multimodal ha aumentado del 4,9% del año pasado al 10,6%, convirtiéndose en una de las áreas de investigación de más rápido crecimiento en los últimos años, donde la percepción en tiempo real y la localización son las dos palabras clave más destacadas.
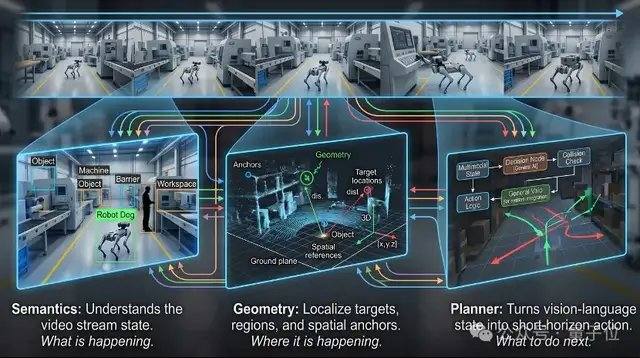
VLX-Flow se encarga de la percepción continua. En el mundo real, los objetos están siempre en movimiento, el entorno cambia constantemente y las perspectivas cambian con frecuencia, por lo que una observación única difícilmente puede hacer frente a un entorno dinámico, abierto y en constante cambio. Los modelos de video tradicionales a menudo dividen todo el video en fotogramas y los envían al modelo para su comprensión fuera de línea. Cuando el video es largo, no solo el costo computacional aumenta drásticamente, sino que también es fácil perder información anterior. Flow utiliza procesamiento de flujo continuo, donde las imágenes fluyen continuamente como agua. Dependiendo de la codificación incremental y un mecanismo de caché, actualiza continuamente el estado visual sin necesidad de recalcular el historial repetidamente ni perder memoria debido al aumento de la longitud del video. A nivel técnico, Flow utiliza Attention Lineal en lugar de Attention estándar, combinado con un mecanismo de memoria de doble capa, lo que permite que el flujo de video entre continuamente al modelo sin que el crecimiento del contexto provoque una explosión de la memoria de video.

VLX-Seek se encarga de la percepción detallada. Aunque muchos modelos de lenguaje visual generales son buenos en la comprensión semántica de alto nivel, tienen un rendimiento limitado en tareas como la localización precisa, la detección de vocabulario abierto y la localización de grano fino (Grounding). Los métodos tradicionales utilizan un enfoque autorregresivo, prediciendo la posición del objetivo coordenada por coordenada, lo que es lento y propenso a errores. Seek cambia el enfoque: ya no adivina coordenadas, sino que primero genera regiones candidatas y luego completa la búsqueda y el emparejamiento, convirtiendo el proceso de localización en una selección de regiones. Específicamente, Seek utiliza Region Token en lugar de la generación tradicional de coordenadas, lo que reduce significativamente el tamaño del modelo y el costo de implementación en dispositivos de borde, manteniendo al mismo tiempo la capacidad de reconocimiento. Este enfoque se adapta mejor a las tareas de percepción visual, por lo que incluso con un modelo más pequeño, puede mantener un rendimiento estable en tareas como detección de vocabulario abierto, localización de grano fino y seguimiento en tiempo real.

VLX-Go se encarga de la acción. Incluso si un modelo de lenguaje visual tradicional sabe que el objetivo está al frente a la izquierda, la mayoría de las veces se queda en la etapa de respuesta textual. Para realmente caminar hacia allí, esquivar obstáculos y seguir al objetivo continuamente, se necesita un sistema de control adicional. Go toma como entrada video monocular, memoria visual histórica e instrucciones en lenguaje natural, y los procesa directamente en waypoints a corto plazo ejecutables por el robot, prediciendo cómo debe moverse en un período corto de tiempo futuro, en lugar de solo generar sugerencias textuales. Go combina aprendizaje de trayectorias fuera de línea y aprendizaje por refuerzo en línea, corrigiendo continuamente las estrategias de movimiento en un bucle cerrado de simulación, lo que permite al robot ajustar continuamente su trayectoria basándose en la retroalimentación visual en tiempo real, manteniendo un rendimiento estable en tareas como seguimiento de objetivos, navegación y evitación dinámica de obstáculos. Para satisfacer las necesidades de control en tiempo real en dispositivos de borde, Go adopta un esquema ligero de predicción de waypoints a corto plazo, completando la planificación de movimiento en tiempo real con solo 0.6B de parámetros.
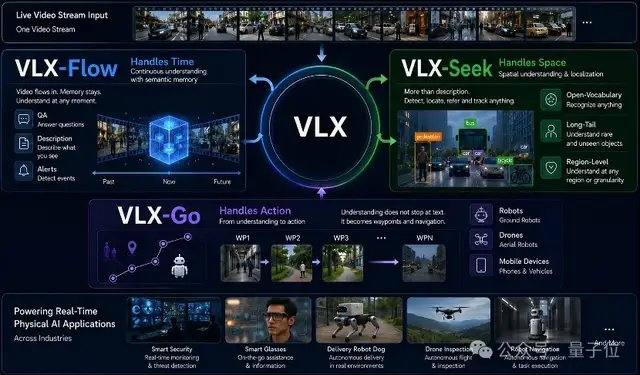
Los tres modelos, Flow, Seek y Go, no son independientes entre sí, sino que comparten la misma base y completan una colaboración de extremo a extremo en el mismo flujo de video. Desde la percepción continua hasta la localización precisa y la toma de decisiones de acción, los tres juntos forman una cadena de capacidades completa de VLX para el mundo físico.
Para dispositivos del mundo físico como robots, drones y cámaras, la implementación en dispositivos de borde es un requisito previo para que el modelo se aplique realmente. Aunque muchos modelos multimodales en la nube ya son lo suficientemente potentes, no son naturalmente adecuados para escenarios robóticos e incorporados, porque el mundo real es continuo, dinámico y con recursos limitados. El enfoque común en la industria es primero entrenar un modelo lo más grande posible y luego comprimirlo para su ejecución en dispositivos de borde mediante cuantización, destilación, etc. VLX eligió un camino diferente, rediseñando todo el sistema desde el principio según las restricciones computacionales de los dispositivos de borde. La arquitectura del modelo, el método de inferencia y el enlace de implementación están diseñados en torno a flujos de video en tiempo real y dispositivos de borde.
Los datos muestran que VLX-Flow procesa un solo flujo de video en solo 0.06 segundos como mínimo, mientras puede manejar de manera estable múltiples flujos de video; VLX-Go logra un rendimiento de navegación superior al de modelos más grandes con solo aproximadamente una décima parte de los parámetros; VLX-Seek, con un modelo de nivel 3B, alcanza o incluso supera el rendimiento de modelos generales más grandes en tareas como la detección de objetos.

Om AI es una empresa de inteligencia artificial con sede en Hangzhou. Su fundador y CEO, Zhao Tiancheng, tiene un doctorado en Ciencias de la Computación de la Universidad Carnegie Mellon y es ganador del Premio de Avance en Ciencia y Tecnología de Inteligencia Artificial Wu Wenjun. Los miembros del equipo provienen de instituciones como CMU, Tsinghua, Zhejiang University, Microsoft y Alibaba Cloud, y cuentan con más de 50 artículos en conferencias principales y más de 50 patentes de invención. En 2022, Om AI obtuvo la primera certificación de modelo multimodal del Ministerio de Industria y Tecnología de la Información de China. El VLX lanzado esta vez es el último logro de la empresa en torno al objetivo de percepción continua, localización precisa y acción real.

Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com