es.wedoany.com Noticia: Netflix ha optimizado la eficiencia de las consultas en la base de datos Apache Druid mediante la introducción de una estrategia de caché consciente de intervalos, logrando que aproximadamente el 84 % de los resultados analíticos provengan de la caché, reduciendo la carga de consultas en aproximadamente un 33 % y mejorando el tiempo de consulta P90 en un 66 %. Esta optimización se implementa principalmente a través de una capa de proxy de caché externa, que aborda el problema de cálculos redundantes y escaneos repetidos de grandes conjuntos de datos causados por ligeros desplazamientos en los rangos de tiempo durante las consultas de actualización continua en paneles de ventana deslizante.
A la escala de Netflix, su sistema de análisis en tiempo real debe procesar billones de filas de datos, proporcionando soporte de paneles para monitoreo, experimentación y toma de decisiones operativas. Estos paneles ejecutan con frecuencia consultas casi idénticas, como calcular tasas de error o métricas de participación dentro de ventanas de tiempo deslizantes. Evan King, cofundador de Hello Interview, señaló que la caché tradicional trata las consultas repetidas con la misma intención pero con pequeños desplazamientos en los límites de tiempo como solicitudes diferentes, lo que resulta en una baja tasa de reutilización de la caché y cálculos repetidos en Apache Druid.
El método de Netflix descompone los resultados de las consultas en segmentos alineados temporalmente para permitir su reutilización en consultas de ventana deslizante superpuestas. En lugar de almacenar en caché la salida completa de la consulta, el sistema almacena agregaciones intermedias en intervalos de tiempo fijos. Cuando llega una nueva consulta, los segmentos en caché se utilizan para la parte histórica relativamente estable dentro de la ventana de tiempo, y solo los datos del intervalo de tiempo más reciente se recalculan desde Druid y se combinan con los resultados en caché.
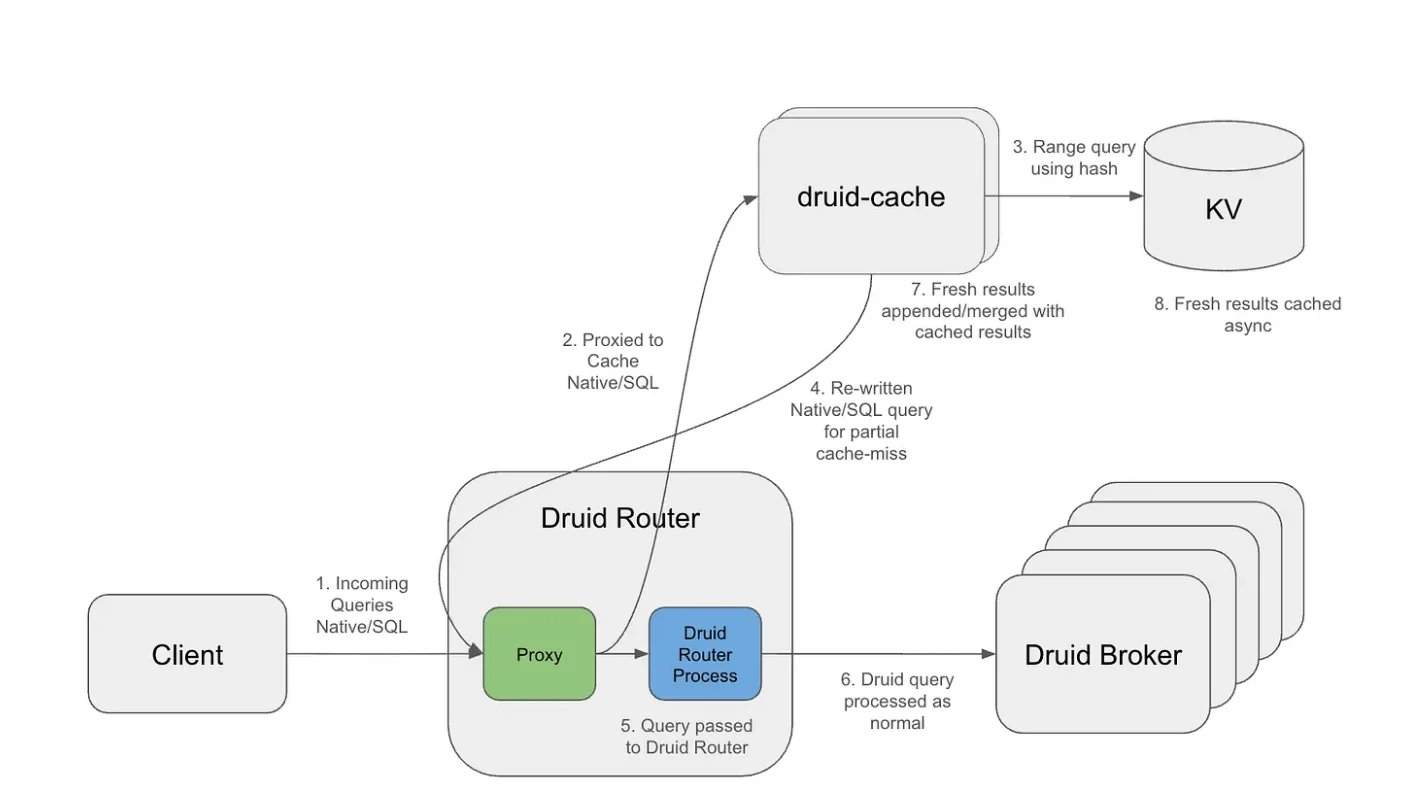
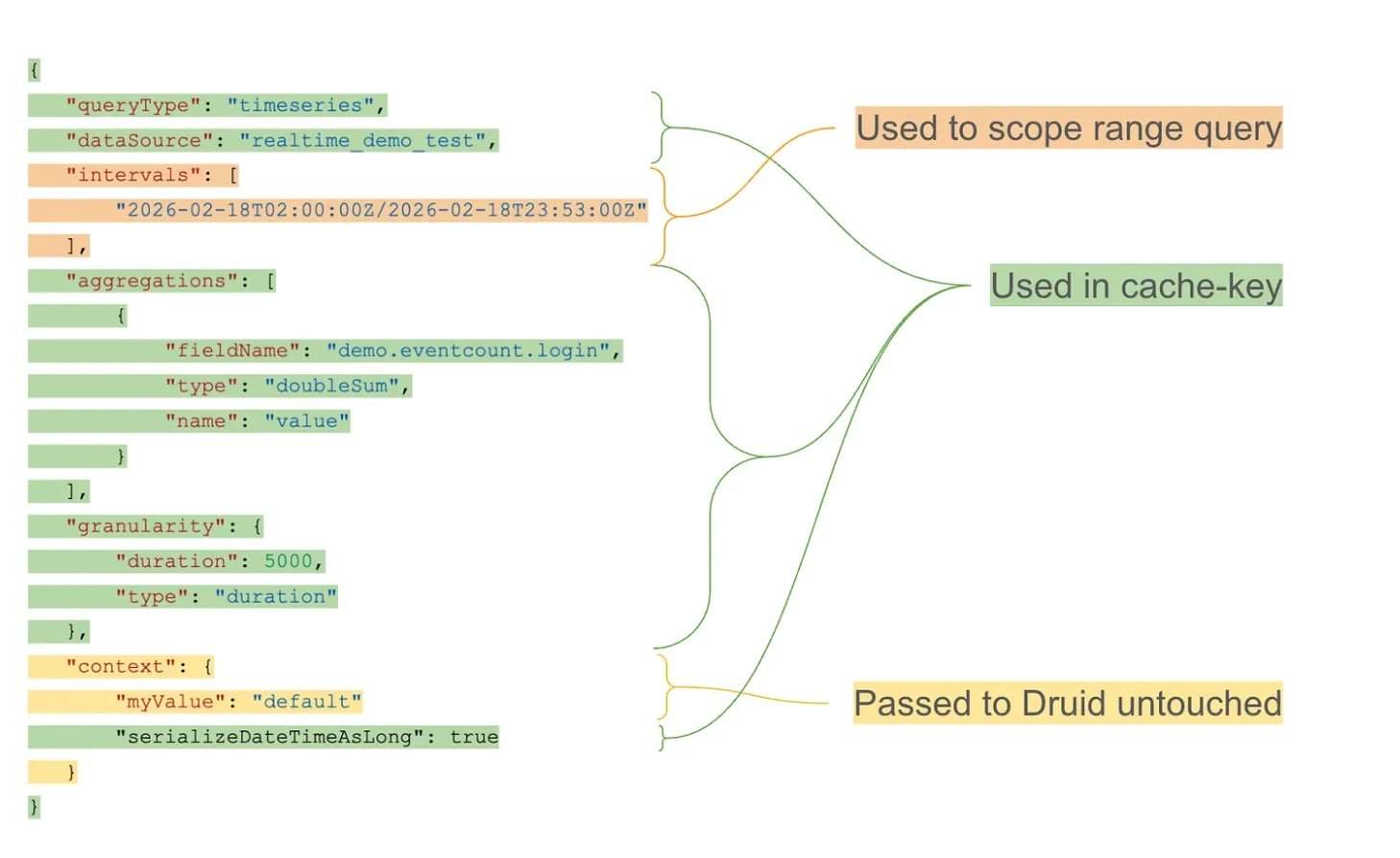
Bajo una carga de trabajo de más de 10 billones de filas de datos en Apache Druid, las consultas repetidas de ventana deslizante se convirtieron en el principal cuello de botella. La capa de caché, mediante el uso de buckets alineados por granularidad y una estrategia de TTL (tiempo de vida) exponencial, logra un almacenamiento en caché a largo plazo de los intervalos históricos, manteniendo al mismo tiempo la actualidad de los datos más recientes. Arquitectónicamente, la capa de caché se ejecuta como un proxy externo que intercepta las consultas entrantes, separa la estructura de la consulta del intervalo de tiempo y genera claves de caché reutilizables. Los segmentos en caché se almacenan en un sistema de clave-valor distribuido, que permite la expiración independiente y la recuperación eficiente.
Con este diseño, solo el intervalo más reciente necesita ser recalculado, mientras que los segmentos históricos pueden reutilizarse en múltiples consultas superpuestas. Como resultado, el rango de tiempo de las operaciones de consulta que llegan a Druid se reduce significativamente, se escanean menos segmentos y se procesa menos cantidad de datos. En ciertas cargas de trabajo, Netflix observó una reducción de hasta 14 veces en los bytes de resultados y una disminución sustancial en el escaneo de segmentos.
Actualmente, el sistema está implementado como una capa experimental y continúa evolucionando. El trabajo futuro incluye ampliar el soporte para consultas SQL parametrizadas utilizadas por herramientas de paneles, con el fin de reducir la dependencia de expresiones de consulta nativas de Druid. Netflix también está explorando la integración directa de la caché consciente de intervalos en Apache Druid para eliminar la necesidad de una capa de proxy externa y mejorar la eficiencia de la planificación de consultas.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com