
es.wedoany.com Noticia: El 10 de junio de 2026, Zilliz, con sede en Redwood City, California, anunció que su Zilliz Vector Lakebase ha entrado en la fase de vista previa pública. Se trata de una importante actualización de Zilliz Cloud, diseñada para combinar una base de datos vectorial de nivel de producción con una base de datos nativa de lago compartida.
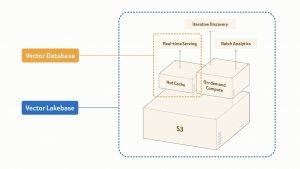
Vector Lakebase se basa en la búsqueda vectorial en tiempo real de Zilliz Cloud, un motor que ya sirve a Zillow, OpenEvidence, Exa, Filevine, MiniMax y más de 10,000 empresas y equipos de IA. Esta actualización amplía tres nuevas formas de operar con los mismos datos: descubrimiento interactivo, análisis por lotes a gran escala y búsqueda directa en lagos de datos externos. El resultado es una única base de datos donde todas las cargas de trabajo operan sobre una única copia lógica de los datos, y las tareas bajo demanda y por lotes solo se facturan cuando la computación está activa.
Charles Xie, fundador y CEO de Zilliz, afirmó que la búsqueda vectorial de nivel de producción es el núcleo de la empresa y la razón por la que miles de equipos eligen Milvus y Zilliz Cloud. Vector Lakebase es el siguiente paso que Zilliz considera necesario: una base de datos donde el mismo vector puede servir para consultas de producción, respaldar sesiones de descubrimiento y canalizar datos de entrenamiento a escala de petabytes, sin necesidad de réplicas, migraciones ni pilas paralelas.
En cuanto a la importancia de una base de datos única, los sistemas de IA ya no son un problema de recuperación de consultas única. Operan en un ciclo continuo que incluye servir, aprender de la retroalimentación, extraer y preparar mejores datos, y luego servir nuevamente. Cada etapa suele requerir sistemas independientes para servicio, exploración y procesamiento a gran escala. Mover miles de millones de vectores entre estos sistemas puede llevar días. Vector Lakebase cierra esta brecha mediante un plano de datos semántico de copia cero construido sobre almacenamiento nativo de lago compartido, permitiendo que el servicio en tiempo real, el descubrimiento interactivo y el análisis por lotes operen sobre una única copia lógica de los datos, escalando desde GB hasta PB.
Robert Guo, vicepresidente de producto de Zilliz y uno de los arquitectos de Milvus, indicó que el equipo buscaba una forma de mantener los datos en un solo lugar y ejecutar cargas de trabajo muy diferentes sobre ellos. Vector Lakebase logra esto mediante una capa de almacenamiento unificada sobre Vortex, un servicio por capas para la ruta de producción y computación bajo demanda para todas las demás necesidades.
Vector Lakebase ofrece cinco capacidades clave sobre una base única. Primero, el servicio en tiempo real por capas proporciona tres niveles de producción optimizados para diferentes cargas de trabajo: optimizado para rendimiento (1000+ QPS, latencia de milisegundos individuales, en memoria), optimizado para capacidad (100–500 QPS, latencia inferior a 100 ms, memoria más NVMe) y almacenamiento por capas (10–50 QPS, latencia de aproximadamente 100 ms, abarcando memoria, NVMe y almacenamiento de objetos, con costos significativamente reducidos). Todos los niveles tienen una tasa de recuperación predeterminada del 95–98%, ajustable a más del 99%, y están respaldados por el SLA de disponibilidad del 99.99% de Zilliz Cloud y la alta disponibilidad entre regiones de clústeres globales. Segundo, la búsqueda bajo demanda ofrece computación de pago por uso para cargas de trabajo donde la infraestructura permanece inactiva la mayor parte del tiempo, facturando directamente el almacenamiento de objetos y la computación. Las pruebas internas de Zilliz con mil millones de vectores de 768 dimensiones y 10 horas de computación activa al mes mostraron que la búsqueda bajo demanda costó un total de 318 dólares, mientras que una ruta sin servidor similar requeriría 4,937 dólares, aproximadamente 1/15 del costo. Tercero, la búsqueda en lagos de datos externos es un modo de colección externa de copia cero que añade índices de última generación y búsqueda de espectro completo a tablas existentes de Lance, Iceberg, Parquet y Vortex, con sincronización incremental durante la actualización, manteniendo los datos fuente en su ubicación original. Cuarto, la búsqueda de IA de espectro completo admite búsquedas en vectores (densos y dispersos), texto, JSON y datos geoespaciales, con soporte para recuperación híbrida, BM25, expresiones regulares, búsqueda multivectorial e iterativa, y recuperación de múltiples rutas. Los resultados se pueden reordenar utilizando Cohere, Voyage AI, RRF, así como estrategias de ponderación, mejora o atenuación. Quinto, el almacenamiento nativo de lago unificado se basa en Vortex para construir almacenamiento compartido entre servicios y análisis. Vortex es un formato de columna abierto diseñado para lecturas aleatorias más rápidas y económicas que Lance y Parquet, combinado con índices conscientes del almacenamiento de objetos, reduciendo la amplificación de lectura en más del 90%. Un relleno de esquema de 100 millones de filas suele completarse en minutos de un solo dígito, sin interrumpir el tráfico de consultas activas.
Estas capacidades permiten a los equipos de IA consolidar los clústeres de servicio paralelos siempre activos y los sistemas por lotes independientes que antes eran necesarios en una sola plataforma, con índices consistentes, datos versionados y recursos de computación que pueden reducirse a cero entre tareas.
Zilliz Vector Lakebase ya está disponible en vista previa pública en Zilliz Cloud, con opciones de implementación sin servidor, dedicada y BYOC, que cubren más de 30 regiones en AWS, Google Cloud y Microsoft Azure. El registro con un correo electrónico laboral otorga un crédito gratuito de 100 dólares. Los equipos que ejecutan servicios, descubrimientos y análisis en pilas independientes pueden contactar al equipo de Zilliz para obtener una guía personalizada.
Zilliz es una empresa de infraestructura de datos de IA y la creadora de la base de datos vectorial de código abierto Milvus, que cuenta con más de 44,000 estrellas en GitHub y más de 100 millones de descargas de Docker. Zilliz ayuda a empresas y startups de IA a hacer que sus datos no estructurados sean buscables, analizables y gobernables. Su tecnología se centra en Milvus y Zilliz Cloud. Milvus es una base de datos vectorial de código abierto diseñada para la búsqueda de vectores a escala de cien mil millones. Zilliz Cloud extiende esta base a una plataforma Vector Lakebase completamente gestionada, combinando la capacidad de alto rendimiento y baja latencia de una base de datos vectorial con la apertura, escalabilidad y economía de un lago de datos multimodal. Zilliz respalda a más de 10,000 empresas y startups nativas de IA en todo el mundo, incluyendo MiniMax, OpenEvidence, Filevine, Exa, Salesforce y Read AI. La empresa tiene su sede en Redwood Shores, California, y cuenta con el apoyo de inversores como Prosperity 7 Ventures de Aramco, Pavilion Capital de Temasek, Hillhouse Capital, 5Y Capital, Yunchuang Capital y Trustbridge Partners.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com










