es.wedoany.com Noticia: Microsoft ha lanzado recientemente un nuevo marco de código abierto llamado SkillOpt, diseñado para convertir los documentos de habilidades de los agentes de IA en objetos entrenables. Al introducir métodos de optimización similares al aprendizaje profundo, mejora sistemáticamente el rendimiento de los agentes en tareas complejas.

En aplicaciones de IA empresarial, las habilidades de los agentes suelen existir en forma de archivos Markdown basados en texto, que contienen instrucciones para guiar al modelo a adaptarse a flujos de trabajo específicos. Sin embargo, la optimización tradicional de estas habilidades depende de la edición manual, un proceso lento y propenso a errores, donde los usuarios a menudo necesitan probar repetidamente para encontrar combinaciones de instrucciones que mejoren el rendimiento. SkillOpt aborda este problema. Este marco (con licencia MIT) trata los documentos de habilidades como objetos entrenables que pueden ajustarse iterativamente según la retroalimentación de rendimiento, logrando una adaptación programática a nivel de documento sin modificar los pesos del modelo subyacente.
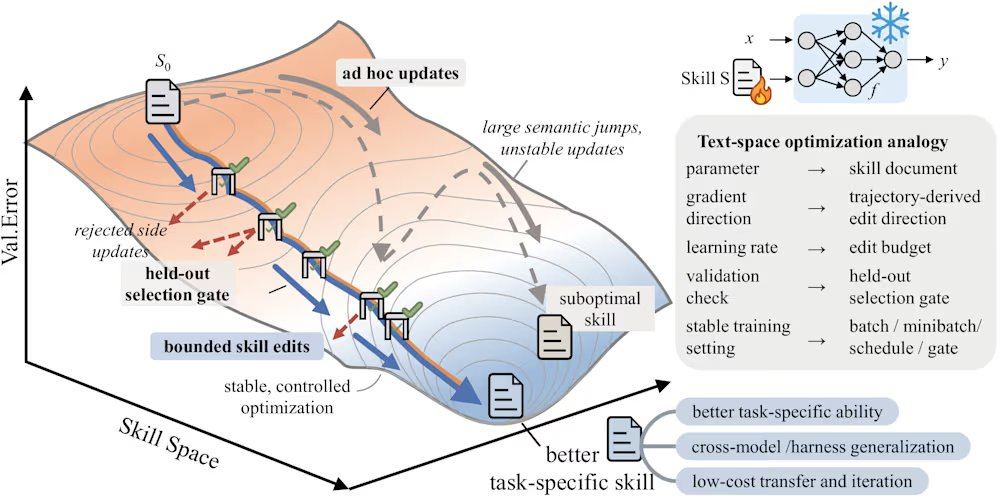
Yifan Yang, ingeniero de investigación senior de Microsoft Research Asia, señala que la edición manual de documentos de habilidades enfrenta tres modos de fallo: falta de control de paso que provoca desviación de habilidades, ausencia de mecanismos de verificación que hace que modificaciones aparentemente correctas puedan causar una caída en el rendimiento, y falta de memoria de retroalimentación negativa que lleva a la repetición de los mismos errores. Por ejemplo, una reescritura sin restricciones en el punto de referencia SpreadsheetBench redujo GPT-5.5 de 41.8 a 41.1. Yang enfatiza que estos errores se amplifican en flujos de trabajo de múltiples pasos, que es precisamente el punto débil de los modelos de vanguardia actuales en inferencia de cero disparos.
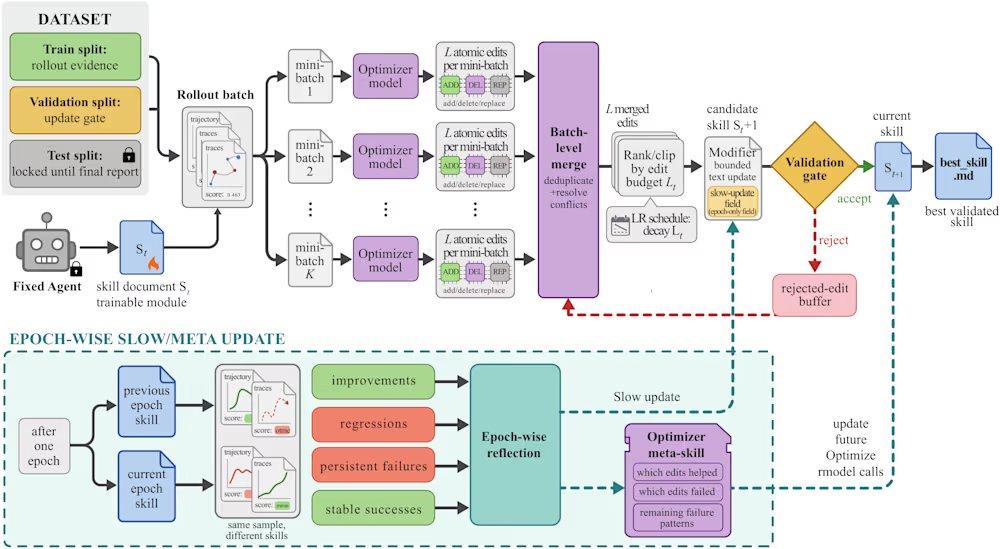
SkillOpt resuelve estos problemas mediante un ciclo iterativo de propuesta y prueba. El proceso comienza cuando un modelo objetivo congelado ejecuta un lote de tareas, generando trayectorias de ejecución como evidencia del estado actual. Luego, un optimizador fuera de línea analiza estas trayectorias, identifica errores programáticos sistemáticos y propone ediciones estructurales al documento de habilidades. Estas ediciones se revisan y clasifican antes de aplicarse, y se limita el presupuesto máximo de edición por paso (similar a la tasa de aprendizaje en aprendizaje profundo) para evitar cambios drásticos en la versión de la habilidad. Las habilidades candidatas se evalúan en un conjunto de validación reservado: si mejoran la puntuación de validación, se aceptan; si fallan, se rechazan y se envían a un búfer de ediciones rechazadas, proporcionando retroalimentación negativa al optimizador. Además, el marco realiza actualizaciones lentas comparando el rendimiento de las tareas entre rondas de habilidades, similar a un término de momento, para transmitir experiencia programática persistente.
En evaluaciones prácticas, el equipo de investigación probó SkillOpt en varios modelos como GPT-5.5, GPT-5.4-mini y Qwen3.5-4B, abarcando puntos de referencia como preguntas y respuestas de una sola ronda, generación de código de múltiples rondas y razonamiento multimodal de documentos. Los resultados muestran que SkillOpt supera a múltiples métodos de referencia, incluidos TextGrad, GEPA y EvoSkill, en las 52 combinaciones de evaluación. En el modelo de vanguardia GPT-5.5, en comparación con la línea base sin habilidades, la precisión absoluta promedio mejoró en 23.5 puntos porcentuales. Para modelos más pequeños como GPT-5.4-nano, las puntuaciones casi se duplicaron o triplicaron. Estas mejoras de rendimiento se traducen directamente en necesidades empresariales clave, como la extracción precisa de números en contratos, facturas y tablas, así como en operaciones como automatización de cuentas por pagar, reclamaciones y cumplimiento normativo. Yang afirma que la mejora radica en la confiabilidad, incluidos formatos precisos, autoverificación y resultados auditables, beneficios que provienen de aprender procedimientos en lugar de memorizar respuestas.
El marco SkillOpt demuestra buena portabilidad y compatibilidad. Los experimentos confirman que es independiente del marco de ejecución, logrando mejoras significativas en entornos de ejecución compatibles con herramientas como Codex CLI y Claude Code. Por ejemplo, una habilidad de hoja de cálculo entrenada completamente dentro del bucle de Codex se puede transferir directamente a Claude Code sin ningún cambio, impulsando una mejora de rendimiento de hasta 59.7 puntos porcentuales en comparación con la línea base nativa de Claude Code. Además, los artefactos de habilidades también se pueden transferir entre diferentes tamaños de modelo: las habilidades optimizadas para GPT-5.4, al implementarse en modelos más pequeños como GPT-5.4-mini y GPT-5.4-nano, siguen generando ganancias positivas. Los documentos de habilidades finales nunca superan los 2000 tokens, con una longitud media de aproximadamente 920 tokens, siendo altamente legibles y auditables.
En cuanto a costos, para casos de uso empresarial cotidianos, la carga real de SkillOpt es ligera. Yang menciona que, en marcos comunitarios como GBrain, las actualizaciones de SkillOpt se ejecutan en Claude Sonnet, con un costo promedio de entrenar una habilidad para una sola tarea de entre 1 y 5 dólares, y este costo de optimización es único. Sin embargo, el funcionamiento efectivo del marco requiere dos condiciones: decenas de ejemplos representativos y una señal de retroalimentación que pueda puntuarse. Los equipos deben evitar aplicarlo a tareas abiertas o subjetivas. Al mismo tiempo, SkillOpt puede funcionar de manera complementaria con pilas de orquestación existentes como DSPy, siendo complementarios en lugar de sustitutivos. De cara al futuro, la comunidad de código abierto ya ha comenzado a implementar ejecuciones periódicas de SkillOpt en trayectorias pasadas de agentes para construir un ecosistema de complementos de agentes de código automejorables. Yang cree que las habilidades son el primer paso más rápido, más barato y más reversible para que la IA descubra conocimiento de forma autónoma y mejore su propio comportamiento, y esta misma forma de pensar apunta hacia que los agentes se optimicen a sí mismos, hasta llegar a sus propios pesos.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com