
es.wedoany.com Noticia: El equipo Qwen de Alibaba ha lanzado Qwen-AgentWorld, que incluye dos modelos. Estos no están diseñados para ejecutar acciones en entornos de agentes, sino para predecir los resultados que dichos entornos devolverán, abarcando siete áreas: MCP, búsqueda, terminal, ingeniería de software, Android, Web y sistema operativo.
Este lanzamiento continúa la reciente apuesta de Alibaba por los agentes autónomos. El Qwen3.7-Max, publicado en mayo, se construyó en torno a una capacidad de ejecución autónoma de 35 horas. El equipo señala que el principal cuello de botella en el entrenamiento de agentes a gran escala radica en las limitaciones del entrenamiento en entornos reales: los motores de búsqueda no pueden inyectar condiciones controladas, los terminales en tiempo real no permiten simular bajo demanda casos extremos como espacio de disco insuficiente, y los agentes difícilmente pueden exponerse sistemáticamente a escenarios poco comunes.
El equipo de investigación entrenó a los agentes en simuladores generados y descubrió que su rendimiento mejoraba más que cuando se entrenaban únicamente en entornos reales. En otra prueba, utilizar el entrenamiento del modelo del mundo como paso de calentamiento previo al ajuste fino del agente mejoró el rendimiento en siete pruebas de referencia, tres de las cuales nunca habían sido vistas durante el entrenamiento. El artículo adjunto señala que la modelización del mundo es un paso clave para lograr agentes universales.
A diferencia de los modelos de agentes tradicionales, que optimizan la selección de acciones, Qwen-AgentWorld se entrena para responder a la pregunta inversa: dado el estado actual del entorno y la acción que el agente acaba de ejecutar, ¿qué mostrará el entorno a continuación? El artículo denomina a este enfoque "modelo del mundo lingüístico", donde el modelo aprende a predecir el siguiente estado del entorno en los siete dominios bajo un único objetivo de entrenamiento. Investigaciones previas relacionadas tenían un alcance más limitado; por ejemplo, WebWorld, publicado por Qwen en febrero, solo cubría entornos web; Agent World Model, publicado por Snowflake el mismo mes, generaba entornos de soporte SQL impulsados por código, en lugar de entrenar modelos para predecir estados. Qwen-AgentWorld es el primer modelo que abarca siete dominios en un solo modelo e integra la modelización del entorno desde la etapa más temprana de preentrenamiento.
El proceso de entrenamiento utilizó más de diez millones de trayectorias de interacción con el entorno provenientes de ejecuciones reales de agentes, dividido en tres fases: la primera fase enseña al modelo cómo funciona el entorno, incluyendo el sistema de archivos, el estado del terminal, los cambios en el DOM del navegador y las respuestas de la API; la segunda fase entrena al modelo para razonar sobre el estado posterior antes de realizar la predicción; la tercera fase, mediante aprendizaje por refuerzo, utiliza verificaciones basadas en reglas y puntuaciones de calidad abiertas para ajustar las predicciones. Ambos modelos adoptan un diseño de expertos mixtos, activando solo una pequeña parte de los parámetros por cada token. El modelo de 35B activa 3B, y el de 397B activa 17B; ambos admiten una ventana de contexto de 256K. Para los dominios GUI (Android, Web y sistema operativo), los modelos trabajan a partir de árboles de accesibilidad textual y jerarquías de vista de la interfaz de usuario, no de capturas de pantalla. Los pesos del modelo de 35B y AgentWorldBench están disponibles bajo la licencia Apache 2.0; los pesos del modelo de 397B aún no se han publicado públicamente.
Las puntuaciones de las pruebas de referencia muestran la precisión con la que el modelo predice el contenido que devolverá el entorno, pero los resultados del entrenamiento revelan el valor práctico de esta capacidad predictiva para construir equipos de agentes, y estas cifras son más importantes. Según los investigadores, los agentes entrenados en simulaciones controladas superan a los entrenados en entornos reales. La inyección de perturbaciones dirigidas elevó MCPMark de 24,6 a 33,8. En tareas de búsqueda, los agentes entrenados en mundos completamente ficticios se transfirieron a tareas de búsqueda reales, mejorando WideSearch F1 Item en el modelo de código abierto de 35B de 34,02 a 50,31. Las pruebas de calentamiento mostraron que el preentrenamiento del modelo del mundo elevó BFCL v4 de 62,29 a 71,25 y Claw-Eval de 53,60 a 64,88, sin necesidad de ningún ajuste fino específico para el agente.
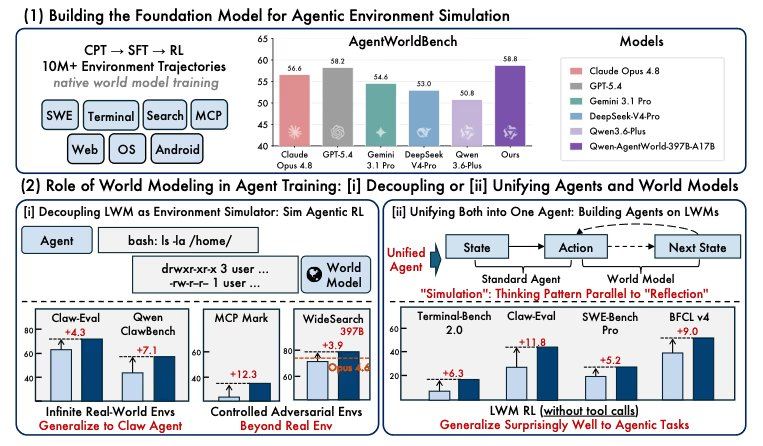
Tras la publicación del artículo, surgió debate entre los investigadores de IA. Algunos opinan que Qwen invirtió el problema central al entrenar al modelo para predecir el entorno en sí mismo, y que este conocimiento predictivo se transfiere posteriormente a las tareas del agente, incluso sin realizar un ajuste fino específico para el agente. Otros investigadores señalan que AgentWorldBench es un punto de referencia construido y publicado por Alibaba en el mismo artículo, y que en las pruebas su modelo ganó por un margen de 0,46, lo que podría generar un escrutinio sobre la independencia de los criterios de evaluación. El problema tradicional del enfoque de RL basado en simulación es que los agentes tienden a sobreadaptarse a las características del simulador; si el modelo del mundo es demasiado limpio, el agente aprende el modelo en lugar de la tarea. Las divisiones de exclusión y los resultados de datos en el artículo responden en parte a estas preocupaciones: los resultados de búsqueda en mundos ficticios muestran que los agentes entrenados en estos entornos pueden transferirse a tareas de búsqueda reales.
Para los equipos que construyen y escalan tuberías de agentes, este trabajo ofrece una tercera opción: simulaciones controladas que inyectan casos extremos que no aparecerían en entornos de producción. Los entornos sintéticos constituyen una capa de entrenamiento legítima, un complemento a la RL en entornos reales, no un atajo para evitarla. La fundamentación del entorno antes del entrenamiento del agente actúa más temprano en el proceso de desarrollo que la mayoría de las prácticas actuales, y puede mejorar el rendimiento en múltiples puntos de referencia sin necesidad de entrenamiento específico para el agente. Lo que el modelo aprende antes del entrenamiento es mucho más importante de lo que la mayoría de las tuberías consideran.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com










