
es.wedoany.com Noticia: El debate sobre la ruta tecnológica de la robótica se convirtió en el foco de la industria durante la Conferencia de la Fuente de la Inteligencia de Beijing en junio. En el último año, con el auge de la industria robótica, ha crecido el debate en el sector sobre si los robots deben seguir la ruta VLA (Visión-Lenguaje-Acción) o la ruta del modelo del mundo. El Dr. Guo Yandong, fundador y CEO de Zhipingfang, dio una respuesta clara en su discurso de apertura en el Foro de CEOs de la Industria de la Corporalización de la conferencia: el modelo del mundo no es una ruta competidora de VLA, sino un componente central de su sistema; tras la fusión del modelo del mundo con VLA, la arquitectura similar al cerebro se convertirá en una dirección importante para la evolución de la próxima generación de cerebros robóticos.

Detrás de esta conclusión se encuentra el despliegue tecnológico de Zhipingfang en los últimos tres años. Guo Yandong considera que, desde la perspectiva de la evolución de la vida, la capacidad de acción no surge de forma aislada; los seres vivos primero perciben y comprenden el entorno antes de generar acciones. Redefinió VLA como un término general para una arquitectura de modelo de extremo a extremo impulsada por grandes datos que fusiona múltiples modalidades, y cree que no hay una diferencia esencial entre el modelo del mundo y VLA, ni una relación de sustitución. El modelo del mundo resuelve la predicción densa y 4D que incluye la dimensión temporal del entorno físico, es parte de la percepción espacial de VLA y ayuda a mejorar las capacidades del cerebro robótico. Guo Yandong puso un ejemplo para explicar por qué ambos deben fusionarse: la lógica de razonamiento cognitivo, como preparar té primero tomando la bolsita y luego vertiendo agua, depende del modelo de lenguaje, mientras que el modelo del mundo es experto en predicciones a corto plazo, como que una taza de agua cerca del borde de la mesa podría caerse; la combinación de ambos permite que el robot tenga tanto predicciones físicas a corto plazo como capacidades de planificación de tareas a largo plazo. Zhipingfang también utiliza el modelo del mundo para generar datos marginales difíciles de recolectar en entornos reales, para complementar el entrenamiento de VLA.
Basándose en esta conclusión, Zhipingfang, en noviembre de 2025, en colaboración con la Universidad de Pekín, lanzó la nueva arquitectura Video2Act que integra el modelo del mundo, logrando por primera vez el paradigma de modelo robótico de "primero predecir, luego ejecutar". Video2Act no es un modelo tradicional de generación de video, sino una arquitectura VLA que integra un modelo del mundo 4D. A través del modelado de información espacial densa y la entrada continua de la secuencia temporal de acciones, permite que el robot comprenda de antemano los cambios futuros del estado y convierta la capacidad de predicción en decisiones de acción. En evaluaciones de terceros, Video2Act logró una mejora de rendimiento superior al 30% en comparación con los modelos más avanzados similares de Silicon Valley. En la revisión autorizada del modelo del mundo "World Model for Robot Learning: A Comprehensive Survey", realizada conjuntamente por académicos de clase mundial como Philip Torr, miembro de ambas academias reales del Reino Unido e investigador de clase mundial en Inteligencia Artificial de Turing, y Pieter Abbeel, pionero en el campo del aprendizaje por refuerzo, Video2Act fue citado como un resultado representativo de la "ruta de fusión del modelo del mundo + VLA".

Después de resolver el problema de la fusión del modelo del mundo con VLA, Zhipingfang se centró en el desafío de cómo hacer que los robots actúen de manera estable y eficiente como los humanos. Guo Yandong presentó en la Conferencia de la Fuente de la Inteligencia el sistema inteligente corporal NeuroVLA, el más reciente lanzamiento de Zhipingfang, que imita al cerebro. Este es actualmente el único sistema inteligente corporal que posee simultáneamente tres capacidades de movimiento biológico: percepción activa, autorrecuperación de fallos y memoria temporal. Guo Yandong señaló que, aunque los robots en la arquitectura VLA actual tienen una capacidad de comprensión relativamente fuerte, aún presentan problemas como respuesta lenta, vibración en los movimientos y alto consumo de energía en entornos reales complejos, debido a que la mayoría de los robots dependen de un único modelo grande unificado para manejar simultáneamente la percepción, el razonamiento y el control.
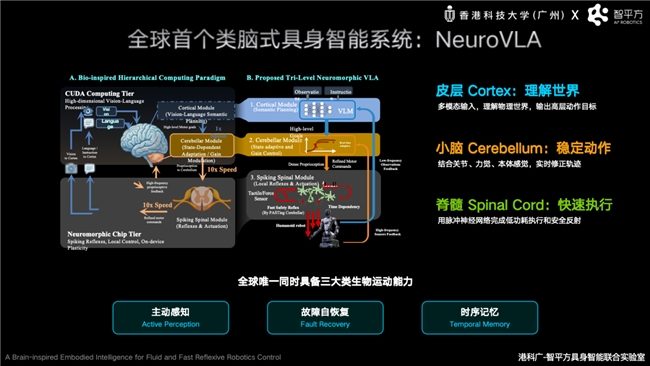
Tomando como referencia el mecanismo en el que la corteza cerebral humana se encarga del pensamiento, el cerebelo de la coordinación del movimiento y la médula espinal de los reflejos instintivos, Zhipingfang construyó la arquitectura NeuroVLA de tres niveles "corteza-cerebelo-médula espinal", pionera a nivel mundial. En ella, la corteza se encarga de la comprensión semántica y la planificación de tareas, el cerebelo de la coordinación de movimientos de alta frecuencia y la corrección dinámica, y la médula espinal de la ejecución de movimientos a nivel de milisegundos y los reflejos de seguridad. Este diseño permite que el robot mejore, desde el nivel arquitectónico, la estabilidad, la capacidad de respuesta en tiempo real y la eficiencia energética en el mundo físico real. Los resultados experimentales muestran que NeuroVLA puede reducir la vibración del movimiento del robot en más del 75%, completar una respuesta refleja en 20 milisegundos después de una colisión y reducir significativamente el consumo de energía del sistema.

Desde el VLA de extremo a extremo, pasando por Video2Act, hasta NeuroVLA, Zhipingfang ha estado realizando innovaciones sistemáticas en torno al cerebro robótico durante los últimos tres años. Esta ruta evolutiva apunta a una misma dirección: dotar a los robots de un "cerebro" más similar al humano.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com









