es.wedoany.com Noticia: Investigadores del IMDEA Software Institute, Nokia Bell Labs, la Universidad Complutense de Madrid, la Universidad de Aalto y Quobly han desarrollado una arquitectura hardware basada en FPGA para la decodificación en tiempo real de códigos LDPC cuánticos. El diseño, publicado en ArXiv, gestiona matrices de errores correlacionados mediante un diseño estructural, optimizando la latencia, el área física y el consumo de energía, y abordando el cuello de botella del procesamiento clásico que desafía la expansión física de la capa de corrección de errores cuánticos. Esta arquitectura utiliza ciclos de reutilización de recursos dirigidos, en lugar de una paralelización hardware ilimitada, para manejar dependencias complejas de síndromes de múltiples qubits.
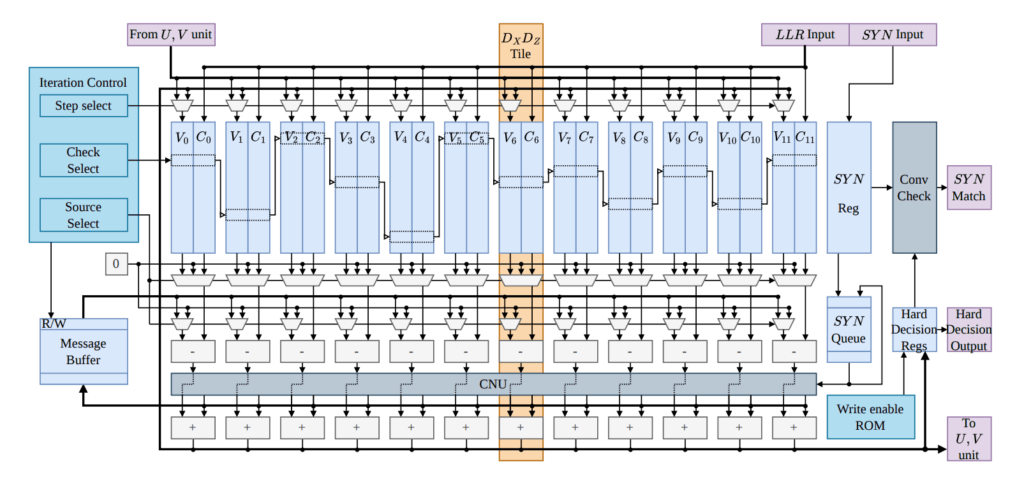
El diseño interno del decodificador se asigna directamente a un marco especializado de mejora y reconexión de grafos (GARI). Los procedimientos de decodificación estándar suelen procesar de forma independiente las coordenadas espaciales de error X y Z, lo que reduce la fidelidad de seguimiento cuando los parámetros de fase y de inversión de bits se vinculan a través de fallos Y combinados. La transformación GARI modifica la matriz del modelo de error del detector subyacente separando las variables correlacionadas y eliminando los bucles 4 cortos que involucran errores Y, reemplazando el grafo enredado por dependencias estructuradas de coordenadas U y V. Esta reestructuración algebraica permite que el hardware distribuya la tarea de decodificación conjunta en rutas de ejecución desacopladas, suprimiendo correlaciones de mensajes perjudiciales mientras mantiene el intercambio iterativo de información entre los dominios de error.
Para ejecutar la matriz reestructurada, la arquitectura divide las tareas de procesamiento en un núcleo de propagación de creencias (BP) y un módulo de seguimiento paralelizado. Las matrices principales DX y DZ se enrutan a través de una unidad BP basada en memoria y de programación en serie, que actualiza secuencialmente los parámetros de cálculo según la regla de suma mínima normalizada. Las estructuras de verificación independientes de las matrices U y V se paralelizan dentro de mosaicos hardware separados, procesando intervalos sincronizados con el núcleo en serie. La interconexión modular cruzada utiliza etapas de ordenamiento por base binaria como un enrutador pipeline N a N, evitando la lógica de control clásica explícita y previniendo la congestión de enrutamiento y las paradas del bus de datos.
Esta implementación hardware se evaluó en una FPGA AMD VCU19P y se asignó a la estructura FPGA VU29P para decodificar el código de bicicleta bivariante [[144,12,12]] dentro de una ventana de 12 rondas consecutivas de medición de síndromes. La arquitectura aplica restricciones de cuantificación numérica, limitando las relaciones de verosimilitud logarítmica (LLR) de entrada a 6 bits, los mensajes de nodos de verificación a 8 bits y los valores de nodos de variable a 10 bits, mientras aproxima la precisión numérica del modelo de seguimiento clásico de punto flotante. Funcionando a una frecuencia de aproximadamente 274 MHz a través de puertos AXI-Stream, el ciclo de ejecución pipeline proporciona una latencia de decodificación promedio de 596 nanosegundos por ronda, cumpliendo con las restricciones de decodificación en tiempo real bajo distribuciones de ruido correlacionadas realistas del hardware.
Un solo núcleo ocupa un área limitada, que incluye el 7.5% del total de tablas de consulta lógica (LUT), el 3.5% de los registros y el 26% de los elementos de RAM de bloque (BRAM) internos, pudiendo asignarse parcialmente a bloques URAM para reducir la presión sobre la memoria. Esta eficiencia de recursos permite que una configuración combinada de tres decodificadores funcione simultáneamente dentro de una sola placa FPGA VCU19P. Una combinación completa de seguimiento de 24 decodificadores concurrentes puede desplegarse en ocho dispositivos hardware físicos, en lugar de las 48 placas que requeriría una arquitectura alternativa completamente paralelizada.
La asignación detallada de recursos de silicio, la derivación de la transformación de matrices y los puntos de referencia de latencia de enrutamiento pueden consultarse en el preprint completo disponible en arXiv.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com