es.wedoany.com Noticia: El 22 de junio, Baidu lanzó como código abierto el modelo Unlimited OCR, cuyo objetivo es resolver el problema de que los modelos OCR de extremo a extremo se vuelven cada vez más lentos al analizar documentos largos. El modelo tiene un total de 3 mil millones de parámetros, y solo se activan 500 millones durante la inferencia.
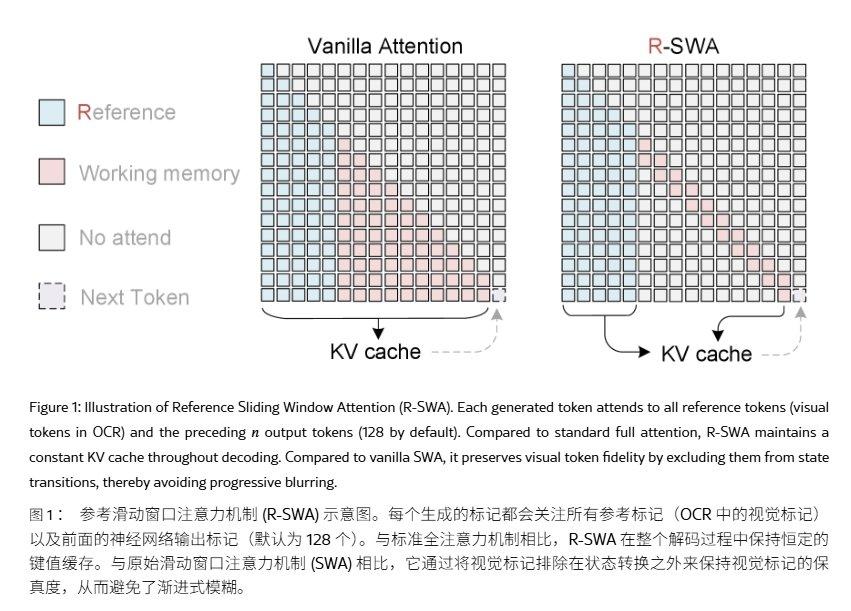
El modelo OCR de extremo a extremo adopta una arquitectura de red neuronal unificada, fusionando la detección de texto y el reconocimiento de caracteres en un solo sistema, mapeando directamente desde la imagen de entrada a la secuencia de texto de salida, eliminando el proceso tradicional de detectar primero los cuadros de texto y luego reconocerlos por separado. Cada vez que un modelo OCR de extremo a extremo genera un token, expande la caché de clave-valor (KV cache), lo que provoca un aumento continuo en el uso de memoria y la latencia, haciendo que el usuario perciba que el análisis de documentos de varias páginas se vuelve más lento a medida que avanza.
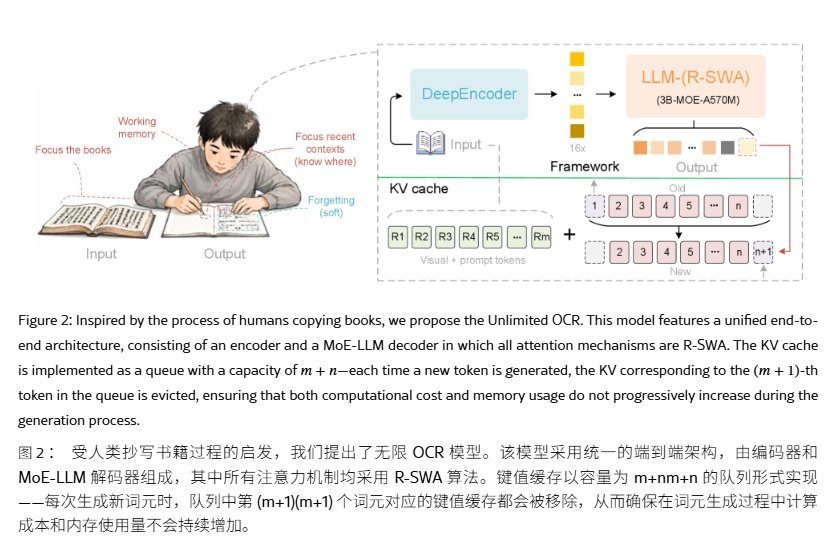
Unlimited OCR continúa la arquitectura de DeepSeek OCR, manteniendo el DeepEncoder y el decodificador de mezcla de expertos (MoE). El lado de codificación utiliza una codificación visual de dos niveles, realizando una compresión de tokens de 16 veces en la etapa de conexión, comprimiendo una imagen PDF de 1024×1024 en 256 tokens visuales, reduciendo la carga de prellenado desde el origen.
En cuanto al entrenamiento, Unlimited OCR se basa en el punto de control de DeepSeek OCR para continuar el entrenamiento durante 4000 pasos, congelando el DeepEncoder y entrenando solo el decodificador. Los datos de entrenamiento consisten en aproximadamente 2 millones de muestras de documentos, ejecutándose en 8×16 GPU A800. La proporción de datos es de aproximadamente 9:1 entre páginas individuales y múltiples, y las muestras de múltiples páginas se obtienen mediante concatenación.
Las pruebas de referencia muestran que Unlimited OCR obtiene una puntuación general de 93.23 en OmniDocBench v1.5, superior a los 87.01 de DeepSeek OCR y los 89.17 de DeepSeek OCR 2. Su distancia de edición de texto es de 0.038, el CDM de fórmulas es de 92.61, el TEDS de tablas es de 90.93, y la distancia de edición de orden de lectura es de 0.045. En OmniDocBench v1.6, la puntuación general del modelo alcanza aún más los 93.92.

Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com