Según datos de InferenceX publicados por SemiAnalysis el 16 de febrero, la arquitectura Blackwell Ultra de NVIDIA ha logrado avances importantes en la economía de la inferencia de IA. Ashraf Eassa, autor de la institución, señala que, en comparación con la plataforma Hopper anterior, el sistema NVIDIA GB300 NVL72 logra una mejora de hasta 50 veces en el rendimiento por megavatio y reduce el coste por token hasta 35 veces. Estas mejoras están dirigidas principalmente a cargas de trabajo de baja latencia y contexto largo, como agentes de codificación de IA y asistentes interactivos. El "Informe sobre el estado de la inferencia" de OpenRouter muestra que este tipo de cargas de trabajo actualmente representan aproximadamente la mitad de las consultas de programación de software de IA, un aumento significativo desde el 11% del año pasado.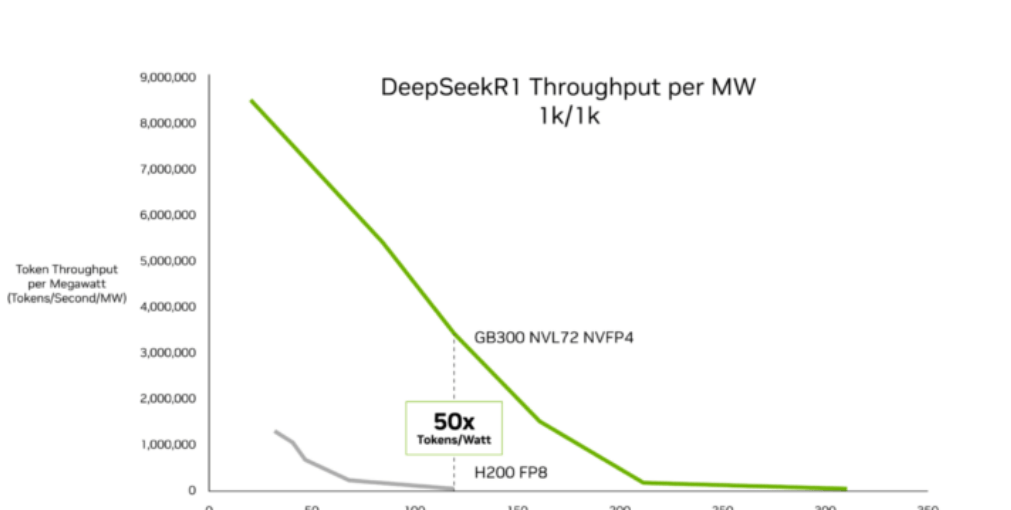
SemiAnalysis atribuye las mejoras de rendimiento a los avances en la tecnología de chips Blackwell Ultra y a la optimización continua de pilas de software como TensorRT-LLM y Dynamo. El GB300 NVL72 integra GPU Blackwell Ultra con memoria simétrica NVLink y reduce los ciclos de inactividad mediante un diseño optimizado de núcleos GPU. En escenarios de inferencia de baja latencia, incluidos flujos de trabajo de codificación de agentes de múltiples pasos, el GB300 NVL72 reduce el coste por millón de tokens hasta 35 veces en comparación con Hopper. Para cargas de trabajo de contexto largo, como entradas de 128.000 tokens y salidas de 8.000 tokens, el GB300 tiene un coste por token hasta 1.5 veces menor que el GB200 NVL72, gracias a las mejoras en el rendimiento computacional NVFP4 y un procesamiento de atención más rápido.
Los proveedores de la nube están desplegando esta plataforma a gran escala. Microsoft, CoreWeave y Oracle Cloud Infrastructure están lanzando sistemas GB300 NVL72 para inferencia en producción de asistentes de codificación y otras aplicaciones de IA de agentes. SemiAnalysis informa que estas mejoras continúan el impulso de despliegue de Blackwell entre los proveedores de inferencia, con sistemas Blackwell tempranos que redujeron el coste por token hasta 10 veces.
Chen Goldberg, vicepresidenta senior de ingeniería de CoreWeave, declaró: "A medida que la inferencia se convierte en el núcleo de la producción de IA, el rendimiento de contexto largo y la eficiencia de tokens se vuelven cruciales. Grace Blackwell NVL72 aborda directamente este desafío, y la nube de IA de CoreWeave está diseñada para convertir las ganancias del sistema GB300 en un rendimiento predecible y eficiencia de costes. El resultado es una mejor economía de tokens, ofreciendo inferencia más accesible para clientes que ejecutan cargas de trabajo a gran escala".
Los datos de SemiAnalysis indican que los hiperescaladores están acelerando la transición hacia infraestructuras optimizadas para inferencia. La hoja de ruta de NVIDIA—desde Hopper hasta Blackwell Ultra y la próxima arquitectura Rubin—posiciona el rendimiento por megavatio y la economía de tokens como principales indicadores competitivos, un área en la que también se centran cada vez más los competidores, incluido AMD.