Investigadores del Instituto Italiano de Tecnología (IIT) y la Universidad de Aberdeen han logrado un importante resultado, trayendo nueva esperanza para mejorar la capacidad de razonamiento espacial de los robots. Propusieron un nuevo marco conceptual y un conjunto de datos con datos generados computacionalmente para entrenar modelos de lenguaje visual (VLM) en tareas de razonamiento espacial; los resultados relacionados se publicaron en un artículo del servidor de preimpresión arXiv, con la esperanza de impulsar sistemas de IA encarnada para navegar y comunicarse mejor con humanos en el mundo real.
Esta investigación es un resultado del proyecto FAIR*, originado en la línea de investigación de cognición social en interacción humano-robot (S4HRI) del IIT (guiada por la profesora Agnieszka Wykowska) y el Laboratorio de Predicción de Acción de la Universidad de Aberdeen (liderado por el profesor Patric Bach).
Davide De Tommaso, experto técnico del IIT y coautor senior del artículo, indica que el grupo de investigación se centra en el uso de mecanismos de cognición social en interacciones entre humanos e IA. Investigaciones previas muestran que, bajo ciertas condiciones, las personas atribuyen intencionalidad a los robots y interactúan con ellos como con socios sociales. Por lo tanto, entender el rol de pistas no verbales como la mirada, gestos y comportamiento espacial es crucial para desarrollar modelos computacionales de cognición social robótica.
La adopción de perspectiva visual (VPT) se refiere a la capacidad de entender escenas visuales desde la perspectiva de otros, que es significativa para sistemas robóticos, ayudándolos a entender instrucciones y colaborar con otros agentes para completar tareas. De Tommaso afirma que el objetivo principal es permitir que los robots razonen efectivamente sobre la percepción de otros agentes en entornos compartidos, como evaluar la legibilidad de texto, si un objeto está obstruido o si la orientación de un objeto es adecuada para el agarre humano. Aunque los modelos base actuales tienen capacidades de razonamiento espacial insuficientes, utilizar modelos de lenguaje grandes para comprensión de escenas y representaciones sintéticas de escenas tiene un amplio potencial para modelar capacidades similares a la VPT humana en agentes de IA encarnada.
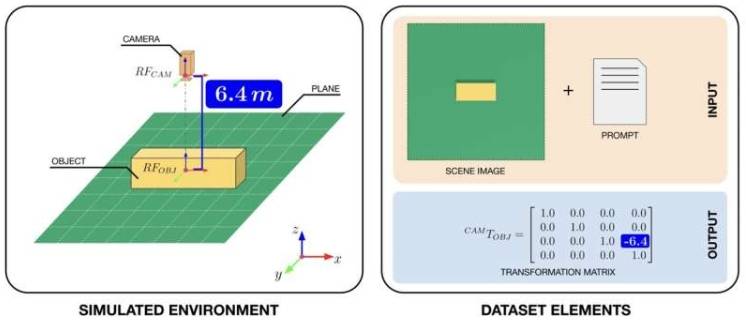
Para mejorar la capacidad VPT de los VLM, los investigadores compilaron un conjunto de datos para apoyar el entrenamiento. Utilizaron la plataforma Omniverse Replicator de NVIDIA para crear un "mundo artificial" compuesto por escenas simples de cubos observables desde múltiples ángulos y distancias. En el mundo simulado, capturaron imágenes 3D de cubos, agregando descripciones en lenguaje natural y matrices de transformación 4x4 (estructuras matemáticas que representan la posición y orientación de los cubos) a cada imagen; este conjunto de datos se ha publicado en línea para que otros equipos entrenen VLM.
Joel Currie, primer autor del artículo, estudiante de doctorado de la Universidad de Aberdeen e investigador del IIT, explica que cada imagen capturada por la cámara virtual viene con indicaciones de texto sobre el tamaño de los cubos y matrices de transformación precisas, permitiendo que los robots planifiquen movimientos e interactúen con el mundo. El entorno sintético es controlable y puede generar rápidamente grandes cantidades de pares imagen-matriz, algo difícil de lograr en escenarios reales, permitiendo que los robots no solo "vean" sino que también entiendan el espacio.
Actualmente, este marco está en etapa teórica, pero abre nuevas posibilidades para el entrenamiento real de VLM. Los investigadores pueden usar el conjunto de datos compilado o datos sintéticos similares para entrenar y evaluar el potencial de los modelos. Currie afirma que el trabajo es esencialmente conceptual, proponiendo un nuevo método para que la IA aprenda el espacio desde su propia perspectiva y la de otros, tratando la VPT como contenido que los modelos pueden aprender a partir de visión y lenguaje, un paso hacia la cognición encarnada y sentando las bases para que las máquinas logren inteligencia social.
La investigación de De Tommaso, Currie, Migno y sus colegas tiene la esperanza de inspirar la generación de más conjuntos de datos sintéticos similares, ayudando a robots humanoides y otros agentes de IA encarnada a mejorar, impulsando su despliegue en el mundo real. Gioele Migno, graduado en IA y Robótica de la Universidad de Roma y recién unido al departamento de investigación S4HRI del IIT, indica que el siguiente paso es hacer que los entornos virtuales sean más realistas, acortando la distancia entre simulación y realidad, lo cual es crucial para transferir el conocimiento de los modelos al mundo real y permitir que los robots encarnados utilicen el razonamiento espacial. Después, también investigarán cómo estas capacidades hacen que las máquinas interactúen de manera más efectiva en escenarios donde los humanos tienen la misma comprensión espacial.