
es.wedoany.com Noticia: Artificial Analysis ha lanzado AgentPerf, el primer benchmark de IA autónoma de la industria, que proporciona a desarrolladores, empresas y proveedores de infraestructura un método estándar para comparar sistemas de IA autónoma. Los resultados de la primera ronda de pruebas muestran que la plataforma NVIDIA Blackwell Ultra NVL72 ofrece un rendimiento líder en cargas de trabajo de IA autónoma, con una cantidad de agentes por megavatio 20 veces superior a la del sistema NVIDIA Hopper.

Las cargas de trabajo de IA autónoma difieren esencialmente de la IA conversacional. Una conversación de chat se completa como una carrera de velocidad, requiriendo solo una llamada al modelo de lenguaje grande (LLM) y una respuesta. En cambio, un agente es más como una carrera de relevos: descompone el objetivo en múltiples pasos y continúa hasta completar la tarea.
Este patrón puede provocar que decenas o cientos de llamadas al LLM se encadenen, donde cada llamada pasa un contexto creciente a la siguiente, y en cada transición se realizan llamadas a herramientas como compilación y ejecución de código, búsqueda en bases de datos y navegación web. La complejidad no es aditiva, sino multiplicativa.
Esta diferencia es crucial para la medición del rendimiento. Los benchmarks de inferencia de IA existentes miden llamadas individuales al LLM, es decir, la velocidad de respuesta del LLM a una sola solicitud y cuántas solicitudes puede manejar el sistema simultáneamente. No están diseñados para cargas de trabajo autónomas, ya que las llamadas encadenadas al LLM, la latencia de las llamadas a herramientas y el contexto creciente ejercen una presión sobre los sistemas de computación acelerada muy diferente a la de una sola llamada al LLM.
Para las empresas que construyen e implementan agentes a gran escala, es fundamental comprender la velocidad de respuesta de los agentes, cuántos se pueden implementar simultáneamente y el trabajo útil que la infraestructura de IA puede realizar por cada dólar invertido y por cada vatio de energía.
En la primera ronda de pruebas, AgentPerf utilizó DeepSeek V4 Pro (un modelo grande de expertos mixtos que representa la categoría de modelos de vanguardia que impulsan los agentes más potentes actualmente) para medir el rendimiento autónomo. Bajo esta carga de trabajo, NVIDIA GB300 NVL72 obtuvo el mayor rendimiento en el benchmark, con una cantidad de agentes por megavatio 20 veces superior a la del sistema NVIDIA HGX H200.
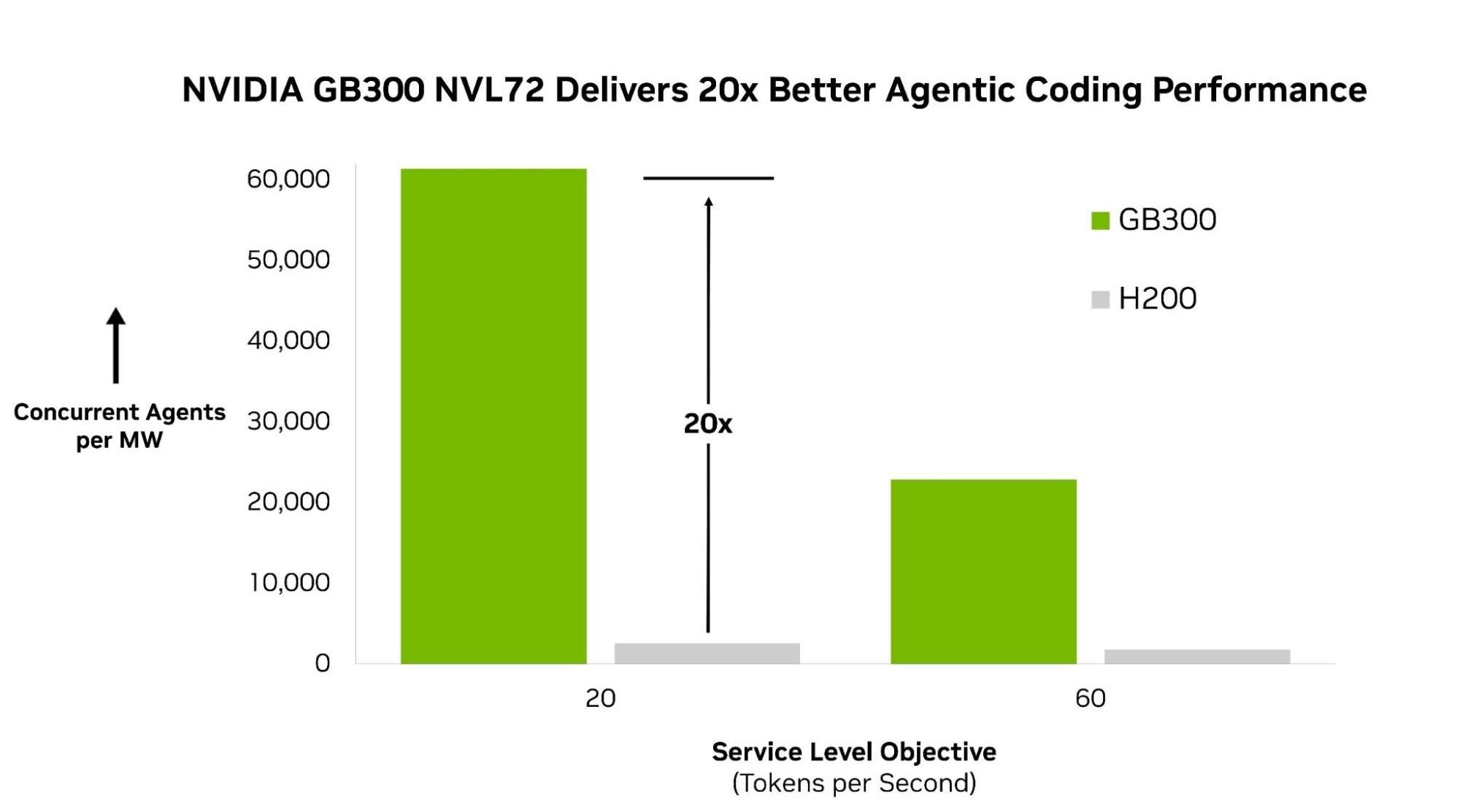
Esta ventaja de rendimiento proviene de un diseño de máxima sinergia en toda la pila. GB300 NVL72 conecta 72 GPU en un sistema a nivel de rack, lo que permite que modelos MoE grandes como DeepSeek V4 Pro se ejecuten de manera eficiente a gran escala distribuida. Los núcleos CUDA aceleran aún más la superposición de comunicación y computación, por lo que el costo de coordinación entre expertos se absorbe sin aumentar la latencia. A medida que escala el número de sesiones de agentes concurrentes, NVIDIA TensorRT LLM mantiene la eficiencia al separar el procesamiento de entrada de la generación de salida, lo que permite optimizar cada etapa de forma independiente. Estos resultados se basan en una metodología de benchmark construida desde cero, diseñada para reflejar cómo funciona realmente la IA autónoma en producción.
AgentPerf se construye a partir de trayectorias reales de agentes de codificación. El agente recibe tareas, lee archivos, escribe y edita código, ejecuta comandos e itera según los resultados, con todos los datos provenientes de repositorios de código público reales en más de 12 lenguajes de programación. Las longitudes de secuencia largas, los patrones de llamadas a herramientas y las latencias representan flujos de trabajo de codificación del mundo real. AgentPerf mide cuántas de estas tareas autónomas puede soportar simultáneamente una plataforma mientras cumple con umbrales de rendimiento predefinidos, como la capacidad de respuesta y la tasa de tokens de salida. Las llamadas a herramientas no se ejecutan realmente, sino que se simulan utilizando tiempos de procesamiento de CPU representativos, por lo que las diferencias en los resultados reflejan únicamente el impacto del rendimiento de la computación acelerada. Los resultados se traducen directamente en decisiones de infraestructura: cuántas tareas autónomas concurrentes se pueden ejecutar por cada acelerador y por cada megavatio de energía.
Proveedores de inferencia líderes, incluidos Baseten, DeepInfra y Together AI, ya están sirviendo cargas de trabajo autónomas en NVIDIA Blackwell para modelos de vanguardia como DeepSeek V4 Pro. Together AI proporciona inferencia en tiempo real en NVIDIA Blackwell para Cursor, una plataforma de codificación autónoma impulsada por IA. Los agentes de Cursor depuran problemas, generan funciones y realizan refactorizaciones mientras los desarrolladores continúan trabajando. DeepInfra respalda a Pam.ai, una plataforma de fuerza laboral de IA para concesionarios de automóviles, que implementa agentes completamente en NVIDIA Blackwell para reservar citas de servicio, manejar llamadas y realizar campañas de ventas salientes. A medida que NVIDIA y el ecosistema de código abierto continúan optimizando el software de inferencia, el rendimiento y la eficiencia de las cargas de trabajo autónomas seguirán mejorando. La arquitectura NVIDIA Vera Rubin ya está en plena producción, lo que traerá la próxima generación de capacidad de infraestructura para satisfacer la creciente demanda de IA autónoma a escala. Para más detalles sobre la metodología de AgentPerf y las optimizaciones de pila completa, consulte el blog técnico correspondiente.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com










