Los investigadores del IPK Leibniz Institute han logrado un nuevo avance en el campo de la predicción genómica de todo el genoma en el mejoramiento vegetal, con resultados publicados en Plant Biotechnology Journal.
Inspirados en el éxito del mejoramiento híbrido de trigo, los investigadores extendieron los métodos de predicción genómica de todo el genoma a líneas endogámicas, integrando por primera vez datos fenotípicos y genotípicos de cuatro proyectos comerciales de mejoramiento de trigo. En los últimos años, los métodos de aprendizaje profundo han ganado importancia en la predicción genómica; en comparación con métodos tradicionales, permiten transformaciones no lineales flexibles de los datos de entrada, identifican patrones en los datos y los asocian con rasgos observables como el rendimiento y la altura de la planta, mostrando ventajas claras cuando los rasgos de las plantas están influenciados por interacciones complejas.
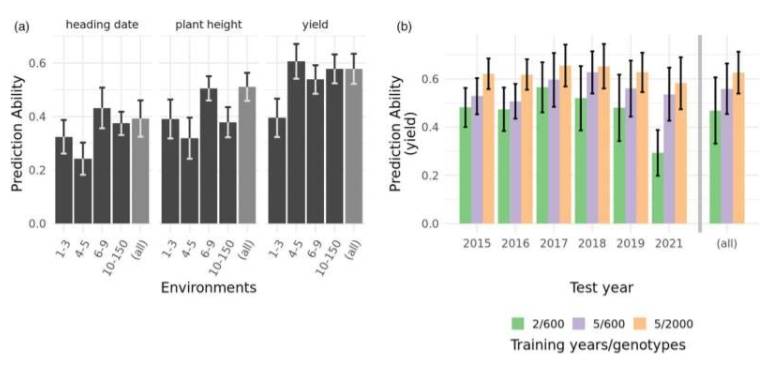
En este contexto, el equipo de IPK asumió el rol de fideicomisario de datos académicos, fusionando datos de cuatro proyectos de mejoramiento de trigo con datos de pruebas tempranas de asociaciones público-privadas. El profesor Jochen Reif, jefe del departamento de “Investigación en Mejoramiento” de IPK, indicó que la investigación requiere datos de múltiples genotipos probados en diferentes entornos (lugares). El nuevo conjunto de datos abarca 12 años de actividades de prueba en 168 entornos, formando un conjunto de entrenamiento de predicción genómica con hasta 9500 genotipos, involucrando rendimiento de granos, altura de planta y época de antesis. Sin embargo, fusionar datos diferentes y hacerlos comparables representa un gran desafío.
A pesar de las diferencias en información fenotípica y genotípica, el equipo de investigación rompió las islas de datos de las bases de datos de las empresas mediante una preparación meticulosa de datos (incluyendo la estimación de SNPs faltantes), obteniendo datos enlazables. Posteriormente, el equipo utilizó estos datos para comparar métodos clásicos de predicción genómica con métodos de aprendizaje profundo basados en redes neuronales, aprovechando las redes neuronales para identificar patrones en datos estructurados.
El primer autor del estudio, Moritz Lell, explicó que el análisis muestra que diferentes secuencias de prueba pueden combinarse de manera flexible para la predicción genómica, y que la precisión de la predicción mejora continuamente al aumentar el tamaño del conjunto de entrenamiento (al menos hasta alrededor de 4.000 genotipos), pero un aumento adicional solo produce mejoras marginales. Ante esto, el profesor Reif enfatizó que incluir más entornos en el conjunto de datos podría superar este cuello de botella, permitiendo un mejor aprovechamiento del potencial del big data en la investigación de mejoramiento.