

Recientemente, investigadores del Instituto Tecnológico de Massachusetts (MIT) han descubierto un "sesgo posicional" en los modelos de lenguaje grandes (LLM) al procesar documentos o conversaciones: los modelos tienden a prestar más atención a la información al principio y al final, ignorando la parte media.
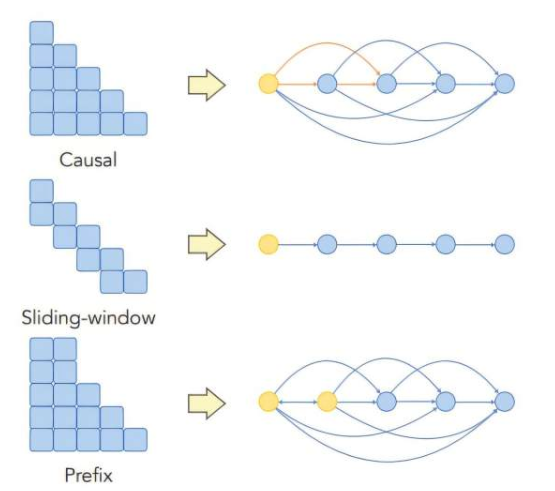
Los investigadores crearon un marco teórico para estudiar en profundidad cómo fluye la información en la arquitectura de aprendizaje automático de los LLM. Descubrieron que tanto la arquitectura del modelo como los datos de entrenamiento pueden causar sesgos posicionales. En particular, los diseños de arquitectura que afectan la propagación de información entre palabras de entrada en el modelo agravan este problema.
"Estos modelos son como cajas negras; los usuarios podrían no saber que el sesgo posicional causa inconsistencias en el modelo", dijo Wu Xinyi, primer autora del artículo. Señaló que, al entender mejor los mecanismos subyacentes del modelo, se pueden mejorar estas limitaciones, lo que llevaría a chatbots más confiables, sistemas de IA médica y asistentes de código.
En los experimentos, los investigadores variaron sistemáticamente la posición de la respuesta correcta en secuencias de texto, revelando un fenómeno de "perdido en el medio", donde la precisión de recuperación muestra un patrón en forma de U. El modelo rinde mejor al principio y al final, pero declina en el medio.
Para abordar este problema, los investigadores propusieron varias estrategias. Descubrieron que usar diferentes técnicas de enmascaramiento, eliminar capas adicionales del mecanismo de atención o adoptar codificaciones posicionales estratégicamente puede reducir el sesgo posicional y mejorar la precisión del modelo.
"Al combinar teoría y experimentos, podemos obtener insights sobre las consecuencias de las elecciones de diseño del modelo", dijo el profesor Ali Jadbabaie. Enfatizó que, en aplicaciones de alto riesgo, es esencial entender cuándo funcionan los modelos, cuándo no y por qué.
En el futuro, los investigadores esperan explorar más el impacto de las codificaciones posicionales y estudiar cómo explotar estratégicamente el sesgo posicional en ciertas aplicaciones. Esta investigación no solo proporciona una perspectiva teórica sobre el mecanismo de atención central de los modelos Transformer, sino que también ofrece referencias importantes para mejorar el rendimiento y la confiabilidad de los modelos.