

En el campo de la inteligencia artificial, sistemas cerrados como ChatGPT y Claude destacan en la comprensión de imágenes complejas como predicciones financieras o gráficos médicos, pero la confidencialidad de sus métodos de entrenamiento y fuentes de datos limita el avance de los modelos de código abierto. Ahora, investigadores de la Escuela de Ingeniería de la Universidad de Pensilvania y del Allen Institute for AI (Ai2) han desarrollado un nuevo método llamado CoSyn que utiliza modelos de IA de código abierto para generar gráficos, diagramas y tablas científicas, proporcionando datos que permiten a otros sistemas de IA aprender a “ver” y comprender información visual compleja.
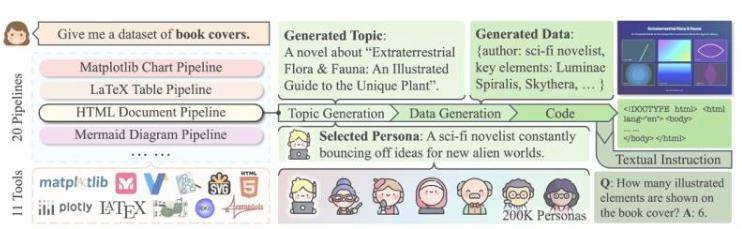
CoSyn (Code-guided Synthesis) aprovecha las habilidades de codificación de modelos de IA de código abierto para incorporar información textual en imágenes y generar preguntas y respuestas asociadas, creando un conjunto de datos con alto valor pedagógico. En el artículo presentado en la conferencia ACL 2025, los autores indican que los modelos entrenados con CoSyn igualan o superan a los modelos propietarios en varios benchmarks. El co-primer autor Yue Yang lo describe metafóricamente: “Es como pedirle a un estudiante excelente en escritura que enseñe a otros a dibujar, simplemente describiendo cómo debería ser el dibujo”.
El conjunto de datos CoSyn-400K incluye más de 400.000 imágenes sintéticas y 2,7 millones de instrucciones, cubriendo áreas como gráficos científicos y estructuras químicas. En la tarea de reconocimiento de etiquetas nutricionales, un modelo entrenado solo con 7.000 etiquetas sintéticas superó a otro entrenado con millones de imágenes reales, demostrando la gran eficiencia de CoSyn en el uso de datos. El profesor Mark Yatskar señala: “Los datos sintéticos ayudan a los modelos a adaptarse mejor al mundo real, por ejemplo, ayudando a personas con baja visión a leer etiquetas nutricionales”. Para garantizar diversidad y evitar repeticiones, el equipo desarrolló la biblioteca de software DataDreamer e introdujo el concepto de “personajes” para guiar la generación de datos variados.
Al construir CoSyn con herramientas completamente de código abierto, el equipo busca romper el monopolio de los modelos propietarios y ofrecer a la comunidad de IA abierta métodos potentes de entrenamiento en lenguaje visual. El profesor Chris Callison-Burch enfatiza: “Esto abre la puerta a sistemas de IA capaces de razonar sobre literatura científica, beneficiando a una amplia población”. Actualmente, el equipo ha publicado el código y el conjunto de datos de CoSyn, invitando a la comunidad investigadora global a seguir explorando. El Dr. Yang Zhiyuan concluye: “Esperamos que la IA pueda actuar en el mundo real, y CoSyn es un paso clave para enseñarle cómo hacerlo”.