es.wedoany.com Noticia: El modelo GLM-5.2 desarrollado por la empresa china de inteligencia artificial Z.ai ha demostrado un rendimiento comparable al del modelo insignia Mythos de Anthropic en la identificación de vulnerabilidades de seguridad de software.

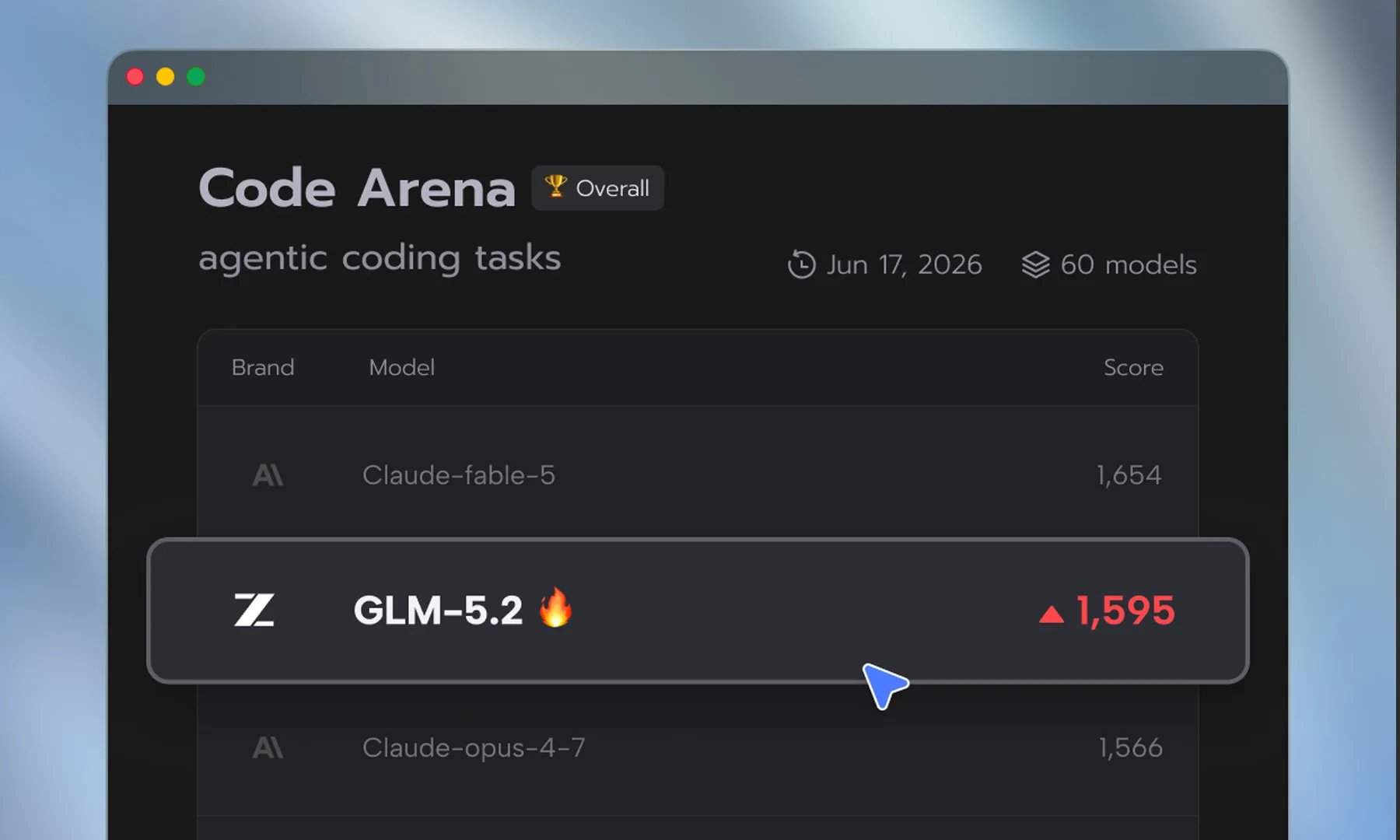
Según un informe de The Wall Street Journal, investigadores de seguridad han descubierto que el GLM-5.2 muestra un rendimiento comparable al de Mythos en la identificación de vulnerabilidades de software. Esta capacidad es crucial en la carrera de las empresas por corregir vulnerabilidades antes de que los hackers puedan explotarlas. El informe también señala que, aunque el GLM-5.2 aún está por detrás de los modelos de Anthropic y OpenAI en tareas de razonamiento general más amplias, la brecha en el ámbito de la ciberseguridad se ha reducido drásticamente. Según los datos de referencia citados, el GLM-5.2 ya ha superado a Claude Opus 4.8 en algunas evaluaciones de seguridad.
El estado de código abierto del GLM-5.2 es un factor diferenciador clave. Cualquier usuario puede descargar, modificar y ejecutar el modelo en su propio hardware sin depender de proveedores de servicios en la nube. Esta flexibilidad resulta atractiva para las empresas, pero también genera preocupaciones sobre su posible uso por parte de ciberdelincuentes con fines de ataque.
Este avance se produce en un momento crítico para la industria de la IA en Estados Unidos. Mientras que empresas como Anthropic y OpenAI restringen el acceso a sus modelos frontera más avanzados por motivos de seguridad nacional, los laboratorios de IA chinos lanzan modelos de pesos abiertos cada vez más potentes. El debate sobre la velocidad de la recuperación china se ha hecho público. Elon Musk predijo anteriormente que los laboratorios de IA chinos alcanzarían al modelo insignia Fable 5 de Anthropic, al menos en rendimiento de referencia, en el primer trimestre de 2027. Tang Jie, fundador de Z.ai, respondió de inmediato diciendo que "no tomaría tanto tiempo". Musk aclaró más tarde que, aunque China podría alcanzar el rendimiento de referencia, alcanzar un nivel de "verdadera utilidad práctica" es un logro más difícil de conseguir.
El informe de The Wall Street Journal añade peso al optimismo de Tang Jie. El informe muestra que el GLM-5.2 ya iguala a Mythos en la detección de vulnerabilidades de seguridad, una de las aplicaciones reales más valiosas de la IA en la actualidad. El modelo de código abierto GLM-5.2 también permite a los investigadores utilizar técnicas de prompting adicionales para lograr un rendimiento comparable al de Mythos, lo que sugiere que los modelos "más débiles" en términos generales pueden optimizarse para tareas críticas específicas mediante métodos adecuados.
Este avance tiene un impacto enorme en la industria de la ciberseguridad. A medida que los modelos de IA de código abierto igualan a los modelos propietarios en la detección de vulnerabilidades, el panorama de la defensa cibernética podría experimentar un cambio radical. Las empresas tienen más opciones de herramientas, pero también se enfrentan a mayores riesgos, ya que las mismas herramientas podrían ser utilizadas por los adversarios. El informe destaca que el foco de la competencia en IA se está desplazando: ya no se trata solo de quién tiene el modelo con el rendimiento de referencia más alto, sino de quién puede convertir las capacidades de la IA en soluciones prácticas y de alto valor en el mundo real. En el ámbito de la ciberseguridad, China ya ha demostrado su capacidad para cerrar la brecha rápidamente.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com