
es.wedoany.com Noticia: Un equipo de investigadores ha desarrollado un marco de entrenamiento para redes neuronales cuánticas que reduce el costo de calcular gradientes durante el proceso de entrenamiento, uno de los principales obstáculos de larga data en el campo del aprendizaje automático cuántico.
Según un estudio publicado en el servidor de preimpresiones arXiv, el método reduce el número de evaluaciones de circuitos necesarias por paso de optimización de un crecimiento cuadrático con respecto al número de qubits a un crecimiento meramente logarítmico. Los investigadores indican que esta mejora permite el entrenamiento basado en gradientes directamente en la computadora cuántica de iones atrapados Forte Enterprise de IonQ, y les permite aplicar el método a una tarea de imputación de datos clínicamente relevante.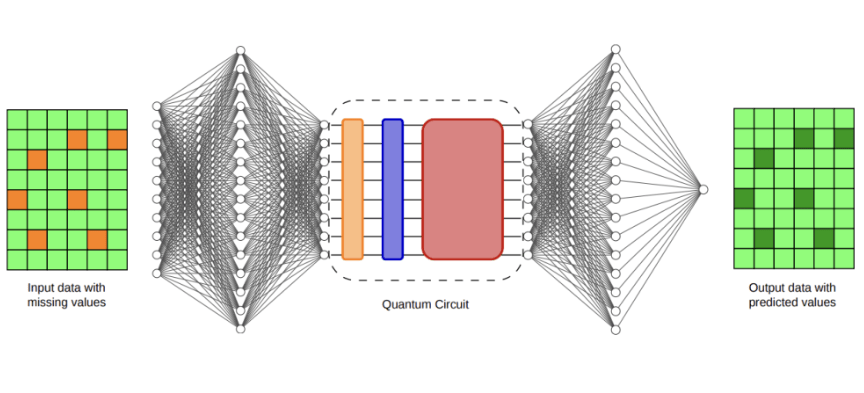
Según el equipo, este trabajo aborda un desafío persistente en el aprendizaje automático cuántico. El equipo incluye científicos de IonQ, la Universidad de París Ciudad (Université Paris Cité), el Centro Nacional de Investigación Científica de Francia (CNRS), QC Ware y Quantum Signals. Las redes neuronales cuánticas (QNN) son circuitos cuánticos con parámetros ajustables que se entrenan de manera similar a las redes neuronales clásicas. En teoría, podrían ofrecer ventajas en ciertas tareas de aprendizaje; sin embargo, entrenarlas en hardware cuántico real ha resultado difícil, ya que calcular gradientes generalmente requiere ejecutar repetidamente una gran cantidad de circuitos cuánticos. Los investigadores informan que este costo es una de las principales razones por las que muchas demostraciones de aprendizaje automático cuántico aún se limitan a simulaciones o experimentos con hardware de escala extremadamente pequeña.
El marco combina tres componentes diseñados de forma conjunta: un diseño de circuito especializado, una estrategia de entrenamiento capa por capa y una técnica de cálculo de gradientes en paralelo.
El método tradicional de desplazamiento de parámetros, ampliamente utilizado para entrenar circuitos cuánticos, requiere evaluaciones de circuito separadas para cada parámetro individual. A medida que el modelo crece en tamaño, el número de evaluaciones necesarias aumenta rápidamente. El nuevo marco evita este cuello de botella mediante tres opciones de diseño. La primera es una arquitectura de circuito denominada red de mariposa (Butterfly network), inspirada en la estructura de la transformada rápida de Fourier, que dispone las operaciones cuánticas en un patrón específico para que la información se propague por todo el sistema, manteniendo el circuito relativamente poco profundo. Según el estudio, este diseño reduce drásticamente el número de parámetros entrenables necesarios a medida que crece el sistema. La segunda es una estrategia de entrenamiento capa por capa: en lugar de entrenar todos los parámetros de la red neuronal cuántica simultáneamente, primero se entrenan bloques de circuitos más pequeños y luego se añaden nuevas capas gradualmente, congelando las capas previamente entrenadas al optimizar las nuevas. La tercera es una versión paralelizada de la regla de desplazamiento de parámetros. Dado que las puertas dentro de cada capa de mariposa actúan sobre diferentes pares de qubits y conmutan entre sí, los investigadores pueden usar un número constante de ejecuciones de circuitos para calcular el gradiente de toda la capa, en lugar de evaluar cada parámetro por separado. En conjunto, estas técnicas reducen significativamente el número de evaluaciones de circuitos cuánticos necesarias durante el entrenamiento. Los investigadores reportan una ventaja de escalado mediante un ejemplo: aplicar el método tradicional de desplazamiento de parámetros a un circuito de mariposa de 128 qubits requeriría 1792 evaluaciones de circuitos para calcular el gradiente, mientras que su método solo necesita 28.
Para evaluar el marco, los investigadores eligieron la imputación de datos clínicos, un problema que va más allá de los puntos de referencia tradicionales de la computación cuántica. La imputación de datos implica completar las entradas faltantes en conjuntos de datos. En los registros médicos, la información faltante es común debido a horarios de medición inconsistentes, fallos de sensores o recopilación de datos incompleta, y una imputación precisa puede afectar significativamente los modelos predictivos posteriores utilizados en el análisis médico. El equipo utilizó el conjunto de datos MIMIC-III, una colección ampliamente estudiada de registros desidentificados de unidades de cuidados intensivos. Introdujeron valores faltantes en el conjunto de datos y luego compararon varios métodos para reconstruir la información faltante. Los puntos de referencia incluyeron técnicas estadísticas comunes como la imputación por la media y el relleno con ceros, así como métodos más complejos como la imputación por K vecinos más cercanos, la imputación múltiple por ecuaciones encadenadas (MICE), MissForest y el modelo Deep MICE basado en redes neuronales. Los investigadores evaluaron indirectamente la calidad de la imputación prediciendo la supervivencia de los pacientes y midiéndola mediante el área bajo la curva característica operativa del receptor (AUC). Entre los métodos clásicos, Deep MICE produjo el rendimiento promedio más fuerte, con un AUC de 0.7176. El modelo híbrido cuántico-clásico entrenado en 16 qubits logró un AUC de 0.7147, mientras que el modelo híbrido de 32 qubits logró un AUC de 0.7132, ambos a menos de unas pocas milésimas del resultado clásico líder. Aunque los modelos cuánticos no superaron la mejor línea base clásica, mostraron un rango de rendimiento estrecho y una baja variabilidad en múltiples ejecuciones. Los investigadores sugieren que esta estabilidad podría indicar un sesgo inductivo beneficioso aportado por la arquitectura estructurada de mariposa y el protocolo de entrenamiento.
El estudio proporciona una demostración importante de entrenamiento directo en una computadora cuántica comercial. Los investigadores entrenaron la última capa de una red neuronal cuántica de mariposa de 16 qubits en el sistema de iones atrapados Forte Enterprise de IonQ. Las etapas iniciales del modelo se entrenaron en simulación y luego se integraron en la red entrenada en hardware. Compararon tres escenarios: simulación ideal, simulación con ruido y ejecución directa en hardware. Según los resultados, las diferencias de rendimiento entre los tres métodos de entrenamiento no fueron estadísticamente significativas; el modelo entrenado en hardware obtuvo resultados comparables a los modelos simulados, manteniendo un rendimiento predictivo similar. Los investigadores informan que esto demuestra que el marco de entrenamiento de escalado logarítmico es lo suficientemente robusto como para funcionar con los niveles actuales de ruido del hardware. Este hallazgo es importante porque muchas demostraciones previas de aprendizaje automático cuántico dependían en gran medida de simulaciones en lugar de procesadores cuánticos reales; el ruido del hardware y los largos tiempos de entrenamiento a menudo hacían que la optimización directa no fuera práctica. La arquitectura de iones atrapados utilizada por IonQ puede haber contribuido, ya que el sistema ofrece conectividad de qubits totalmente conectada, lo que permite implementar el circuito de mariposa sin una sobrecarga significativa de compilación.
La investigación también exploró sistemas de mayor escala. Dado que el entrenamiento directo con 32 qubits sigue siendo computacionalmente intensivo, los investigadores utilizaron simulaciones de redes de estados de productos matriciales para entrenar capas cuánticas más grandes, mientras que la inferencia se ejecutó en hardware de IonQ. El rendimiento del modelo híbrido de 32 qubits resultante fue comparable al de una red neuronal clásica con un ancho de capa oculta equivalente. Los investigadores interpretan esto como evidencia de que los circuitos cuánticos más grandes producidos por el marco capa por capa siguen siendo compatibles con el hardware real y pueden ejecutarse sin una degradación medible.
El trabajo incluye varias limitaciones importantes. El estudio se centró en una tarea de imputación controlada como prueba de concepto, no en un flujo de trabajo médico a escala de producción; solo una columna de características se imputó utilizando el modelo cuántico, mientras que el resto de los valores faltantes fueron manejados por métodos clásicos. El patrón de datos faltantes también se generó utilizando un modelo de ausencia completamente aleatoria, mientras que los datos clínicos del mundo real suelen exhibir patrones de ausencia más complejos. Finalmente, el modelo híbrido igualó, pero no superó, la línea base clásica más fuerte; los resultados demuestran viabilidad y competitividad, no una ventaja cuántica definitiva. Los investigadores también señalan que pueden ser necesarios sistemas más grandes antes de que se hagan evidentes las posibles ventajas de rendimiento. Basándose en comparaciones con arquitecturas de redes neuronales clásicas, estiman que se necesitarían aproximadamente 128 qubits para igualar la capacidad representativa del modelo clásico más fuerte utilizado en el estudio. Aun así, los investigadores consideran que la importancia del marco no reside en las cifras de rendimiento actuales, sino en lograr un entrenamiento escalable en hardware.
El equipo de investigación incluye a Natansh Mathur del Instituto de Investigación en Informática Fundamental (IRIF), un laboratorio de investigación conjunto del Centro Nacional de Investigación Científica de Francia (CNRS) y la Universidad de París Ciudad (Université Paris Cité), así como a QC Ware en Francia. Los coautores Panagiotis Kl. Barkoutsos, Masako Yamada y Martin Roetteler están afiliados a IonQ. La investigación también incluye a Iordanis Kerenidis, afiliado a IRIF, CNRS, la Universidad de París Ciudad y Quantum Signals.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com










