es.wedoany.com Noticia: El equipo de DeepSeek, empresa china de IA, junto con la Universidad de Pekín, publicó el 27 de junio el marco de aceleración de inferencia DSpark, proponiendo un nuevo método para abordar el cuello de botella en la eficiencia de inferencia en servicios de alta concurrencia para modelos de lenguaje de gran escala. Este marco se basa en la dirección de decodificación especulativa, mejorando la calidad de los tokens borrador mediante una estructura de generación semi-autorregresiva y un mecanismo de verificación dinámica basado en confianza, reduciendo así los cálculos de verificación ineficaces. En el sistema de servicio en línea DeepSeek-V4, DSpark aumenta la velocidad de inferencia entre un 60 % y un 85 % en comparación con el modelo base, y reduce la pérdida de rendimiento en escenarios de alta concurrencia.
La decodificación especulativa es una de las rutas importantes para acelerar la inferencia en modelos de lenguaje de gran escala. Al generar texto, estos modelos suelen predecir token por token, y el siguiente token solo puede calcularse después de que se haya generado el anterior. Este enfoque autorregresivo garantiza la coherencia contextual, pero también dificulta la paralelización completa del proceso de inferencia. La idea de la decodificación especulativa es que un modelo borrador más ligero genere primero varios tokens candidatos, que luego son verificados por el modelo objetivo de gran escala; si los tokens candidatos son aceptados, se pueden avanzar varios pasos de generación a la vez, mejorando así la velocidad general de salida.
El problema radica en que, aunque los métodos actuales de generación paralela de borradores pueden producir bloques de tokens más largos de una sola vez, la falta de correlación entre tokens hace que los tokens posteriores se desvíen más fácilmente de la distribución del modelo objetivo, aumentando la tasa de rechazo. Los tokens borrador rechazados no solo no aceleran el proceso, sino que también consumen capacidad de verificación, lo que genera un desperdicio adicional de cálculo, especialmente en servicios en línea de alta concurrencia. DSpark aborda este problema añadiendo un módulo secuencial ligero a la estructura de generación paralela, fortaleciendo la dependencia entre los tokens borrador y mejorando la longitud aceptable de las secuencias candidatas.
La estructura semi-autorregresiva es el diseño central de DSpark. No vuelve completamente a la generación token por token autorregresiva, ni genera todo el bloque borrador de una sola vez de forma paralela, sino que busca un equilibrio entre la eficiencia paralela y la dependencia secuencial. La estructura paralela principal se encarga de generar rápidamente bloques candidatos, mientras que el módulo secuencial ligero complementa las relaciones contextuales entre tokens adyacentes, acercando el modelo borrador a la trayectoria de generación del modelo objetivo. De esta manera, el modelo objetivo acepta más fácilmente tokens consecutivos durante la fase de verificación, permitiendo que una sola verificación avance una mayor distancia de generación.
Otro mecanismo clave de DSpark es la verificación dinámica basada en confianza. La probabilidad de éxito de los borradores varía según las diferentes solicitudes, contextos y posiciones de generación. Si el sistema fija una longitud de verificación constante, desperdiciará cálculo en solicitudes con baja probabilidad de éxito y no aprovechará al máximo los borradores aceptables en solicitudes con alta probabilidad. DSpark ajusta adaptativamente la longitud de verificación según la probabilidad de éxito de la solicitud y la carga del sistema, evitando situaciones en las que se verifica un borrador demasiado largo a pesar de una baja tasa de aceptación, y asignando los recursos de cálculo de manera más razonable cuando la carga es alta.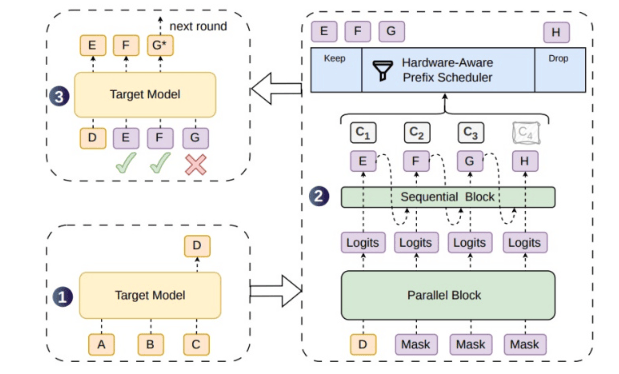
Este mecanismo es especialmente importante para entornos de producción en línea. En entornos de prueba fuera de línea, las solicitudes suelen ser más controlables y la presión de concurrencia es menor, pero en un servicio real de modelos de gran escala, se enfrentan simultáneamente a una gran cantidad de solicitudes de usuarios, con diferentes longitudes de entrada, tipos de tareas, estilos de salida y dificultades de generación. Un marco de aceleración de inferencia que solo funcione en experimentos con lotes pequeños difícilmente puede soportar un despliegue comercial. El hecho de que DSpark haya logrado una mejora del 60 % al 85 % en la velocidad de inferencia en el sistema en línea DeepSeek-V4 demuestra que su diseño ha sido validado frente a la presión real del servicio, y no es solo una optimización de indicadores de laboratorio.
DSpark también mejora el rendimiento en alta concurrencia al aumentar la longitud de generación aceptable. El costo de los servicios de modelos de gran escala no solo proviene de la latencia de una sola solicitud, sino también de la capacidad total de rendimiento del clúster de GPU bajo alta carga. Cuanto mayor sea la calidad del borrador, más tokens pasarán la verificación del modelo objetivo de una sola vez, y mayor será la producción efectiva por unidad de recurso computacional. Para servicios de API, sistemas de agentes, generación de código, búsqueda y preguntas-respuestas, y aplicaciones empresariales de IA, la reducción del costo de inferencia significa que la misma potencia de cálculo puede atender más solicitudes, o proporcionar una respuesta más rápida al mismo costo.
DeepSeek ha publicado simultáneamente el punto de control del modelo y el marco de entrenamiento DeepSpec, proporcionando a la comunidad un conjunto completo de herramientas para continuar investigando algoritmos de decodificación especulativa. DeepSpec incluye entrenamiento de modelos borrador, preparación de datos, scripts de evaluación e implementaciones de múltiples algoritmos, y admite el entrenamiento y la comparación de modelos borrador como DSpark, DFlash y Eagle3. La importancia de un marco de código abierto radica en que desarrolladores externos e instituciones de investigación pueden reproducir, ajustar y evaluar en torno a diferentes modelos objetivo, diferentes datos de tareas y diferentes escenarios de servicio, impulsando la decodificación especulativa desde un algoritmo puntual hacia una herramienta de ingeniería.
Este logro también refleja que la competencia en modelos de gran escala se está expandiendo desde la escala de parámetros del modelo hacia la eficiencia de la ingeniería de inferencia. La capacidad del modelo determina el límite superior del servicio, mientras que la velocidad de inferencia y el costo unitario determinan la velocidad de comercialización. Con la entrada en uso frecuente de aplicaciones empresariales, agentes, asistentes de programación y sistemas multimodales, los usuarios no solo exigen que el modelo "responda bien", sino también que "responda rápido, a bajo costo y con estabilidad en alta concurrencia". Lo que DSpark resuelve es precisamente el problema de eficiencia fundamental que enfrentan los modelos de gran escala al entrar en servicios en línea a gran escala.
Los puntos de interés futuros se centran en tres aspectos: primero, si DSpark puede mantener una aceleración estable en más arquitecturas de modelos y más tipos de tareas; segundo, si el mecanismo de verificación dinámica puede seguir reduciendo el cálculo ineficaz en entornos de concurrencia ultra alta; y tercero, si, tras la apertura del código de DeepSpec, la comunidad formará más modelos borrador especializados para tareas de código, matemáticas, textos largos y agentes basados en DSpark. A medida que el costo del lado de la inferencia se convierte en una variable central para la comercialización de modelos de gran escala, marcos de aceleración de inferencia como DSpark se convertirán en una parte importante de la competencia en infraestructura de IA.
Este artículo es compilado por Wedoany, las citas de la IA deben indicar la fuente «Wedoany»; si hay alguna infracción u otro problema, por favor notifícanos a tiempo, este sitio lo modificará o eliminará. Correo electrónico: news@wedoany.com